Especificación¶
Especificación del sistema Alertas+ - Alertas+ de presiones y amenazas en áreas protegidas.
Versión 1.0.0 - Ciclo v2.0.0 - 2021.
Por Antonio Oviedo, Alana Almeida de Souza, Cicero Augusto, João Ricardo R. Alves, Silvio Carlos, Tiago Moreira dos Santos, William Pereira Lima, Juan Doblas.
Contacto: alertas@socioambiental.org.
Resumen¶
Estudios recientes han demostrado el alto grado de efectividad de las áreas protegidas para mantener la cobertura forestal, lo que refuerza su rol de escudo contra la deforestación y señala la necesidad de fortalecer políticas públicas para la protección de estos territorios. Doblas y Oviedo (2021) analizaron las trayectorias del cambio de uso del suelo a lo largo de 33 años (entre 1985 y 2018) en un conjunto de 1.648 áreas protegidas de ocupación tradicional y zonas de amortiguamiento correspondientes, en todos los biomas brasileños. Los resultados señalan una progresión de la deforestación a lo largo del tiempo, pero con una mayor tendencia en los alrededores de áreas protegidas de ocupación tradicional que en su interior. Las Tierras Indígenas de la Amazonía, por ejemplo, son las áreas protegidas que mejor conservan la cobertura vegetal, es decir, solo el 1,2 % del territorio perdió su cobertura vegetal.
Sumada a los estudios, esta especificación se ocupa de la incorporación, modelado, análisis y provisión de datos para apoyar la producción de conocimiento ambiental sobre áreas protegidas (ARP), así como el desarrollo de un panel de visualización de alertas de deforestación y degradación forestal en la Amazonía Legal brasileña, el sistema Alertas+.
Documenta también decisiones de diseño, ingeniería y supuestos metodológicos utilizados en estimaciones ágiles de alertas de presiones / amenazas territoriales.
El modelado propuesto en el sistema Alertas+ permite la continuidad de la investigación sobre las trayectorias del cambio de uso del suelo y la efectividad de las áreas protegidas. Comprender los factores responsables de las trayectorias de cambio en el uso del suelo es fundamental para la planificación y formulación de políticas públicas de ordenamiento territorial.
Objetivos¶
Alertas+ busca solucionar varios problemas, especialmente en las siguientes dimensiones:
Informativa: responder rápidamente a una variedad de preguntas sobre amenazas que ocurren dentro y fuera de las áreas protegidas;
Narrativa: comunicar explícitamente el papel de las áreas protegidas como «guardianes del bosque» y proveedoras de servicios sociales y ambientales. En los casos en que las áreas protegidas están amenazadas, Alertas+ apoya la identificación de presiones en estos territorios.
Fortalezas¶
Alertas+ tiene las siguientes características:
Resiliencia: no depende de solo una fuente de datos, estando preparado para cualquier problema de acceso, actualización y calidad de fuentes específicas;
Exportación de datos a formatos abiertos;
Los datos disponibles vía API se pueden utilizar en otros sistemas;
Proyecto estructurado para importación, procesamiento y puesta a disposición de datos geoespaciales: se pueden incorporar fácilmente nuevos conjuntos de datos al sistema;
Las importaciones periódicas y automáticas con supervisión humana garantizan un análisis de calidad y casi en tiempo real.
Diferenciales¶
Alertas+ pretende ser un sistema complementario a otros que ya existen, aportando con los siguientes diferenciales:
Llena la brecha de datos con áreas protegidas utilizando la base de áreas trazadas por ISA, ampliamente reconocida por su calidad;
Ofrece una única interfaz en la que se recopilan datos de numerosas fuentes para análisis y comparación;
Permite muchas posibilidades de cruces y preguntas a una base de datos grande y dinámica. El panel de datos de Alertas+ permite el acceso a conjuntos importados, así como a una selección avanzada de recortes temporales y espaciales;
Facilita el uso y la comprensión de los datos, tanto para el público en general como para expertos: el Panel tiene dos modos, básico y detallado, que disponen de la delimitación de un número menor o mayor de posibles preguntas, las cuales ayudan con una curva de aprendizaje suave;
Es multilingüe (portugués, inglés y español);
Funciona en dispositivos móviles;
Realiza estimaciones experimentales de emisiones de carbono;
Se basa en el modelo de ciencia abierta, donde el software libre y los datos abiertos permiten la reproducibilidad de los cálculos, así como la mejora del sistema de manera comunitaria y el aumento de la resiliencia con un mayor número de instancias en uso.
Visión general¶
El diseño de Alertas+ cubrió las siguientes tareas para recopilación y procesamiento de conjuntos de datos:
El desarrollo de un subsistema que realiza la descarga e incrustación de conjuntos de datos a través del cruce con una base geoespacializada de áreas protegidas;
El desarrollo de un subsistema de análisis de datos incrustados, con la discriminación de las clases mapeadas por rangos de período de tiempo arbitrarios (que incluyen, entre otros: diario, quincenal, mensual, anual y total) y de recortes espaciales como Tierras Indígenas (TI), Unidades de Conservación (UC) y respectivas zonas de amortiguamiento (buffers), estados, municipios y cuencas hidrográficas, así como el ofrecimiento de resultados en varias salidas (API, CSV, JSON, GeoJSON y shapefile);
La implementación de rutinas de alimentación periódicas, actualizaciones de la base de datos geográficos, cruces de datos y aporte de varias salidas utilizando el subsistema de descarga e incrustación descrito anteriormente;
La implementación de una API Web mediante el subsistema de análisis ya mencionado.
El análisis de requisitos y modelado de datos propuestos por el equipo de ISA también establece:
El suministro de documentación para bibliotecas, subsistemas y bases de datos desarrollados por el equipo;
Que todo código fuente producido debe ser legible, estar bien estructurado y bien documentado;
Que el código fuente y la documentación se publiquen como software de libre acceso bajo la licencia GNU GPL versión 3 o superior;
Que los datos necesarios para que terceros ejecuten la aplicación también sean hechos disponibles.
Ciclos de desarrollo¶
El diseño inicial del sistema Alertas+ se dividió en dos ciclos:
Ciclo 1: prueba de concepto y estructuración básica (2020):
Desarrollo de rutina para la recopilación y actualización automática de los datos de deforestación del sistema DETER;
Prototipo de frontend de visualización de datos (Alertas+).
Ciclo 2: incrustación de nuevos datos, mejora y lanzamiento público (2021):
Ampliación del conjunto de datos: PRODES (INPE) (incluidos los datos de deforestación acumulada hasta 2007), FIRMS MODIS (NASA), FIRMS VIIRS (NASA), Tablero de la Amazonía (SERVIR) y SAD (IMAZON);
Conversión del prototipo Alertas+ en producto de acceso público.
Código fuente¶
El proyecto generó los siguientes repositorios de código:
Backend: responsable por la incrustación, análisis y disponibilidad de los balances;
Frontend: interfaz web de consulta.
Todo código fuente está disponible bajo la licencia GNU GPL v3.
Datos abiertos¶
Alertas+ es un sistema basado integralmente en datos abiertos:
Utiliza conjuntos de datos de terceros que están disponibles públicamente;
Para los datos compilados por ISA, una página de descargas mantiene los conjuntos generados de forma automática y periódica, los cuales se pueden incrustar de manera automática por instancias de backend.
Datos de terceros están cubiertos por sus respectivas licencias, mientras los datos producidos por ISA están disponibles bajo la licencia Creative Commons CC-BY-SA.
Desglose de la solución¶
E1 - Modelo de datos¶
E1.1 - Entidades y relaciones¶
Las bases de datos modeladas cumplen con el modelo Entidad-Relación de este proyecto según las entidades básicas que se describen a continuación. Sin embargo, tanto las entidades y relaciones finales como el modelo de la base de datos pueden sufrir cambios durante los próximos ciclos de desarrollo, con revisión y ajuste según sea necesario:
Evento de presión / amenaza: también llamado «alerta», es la entidad básica de los balances y se presenta ubicado en el espacio y tiempo. La base de datos debe ser genérica hasta el punto de soportar diferentes tipos de eventos como DETER, focos de incendio FIRMS, etc. Un evento puede ser un punto o área georreferenciada.
Territorio: también adelante llamado de recorte, es la entidad geoespacializada donde ocurren los eventos, como Tierra Indígena (TI), Unidad de Conservación (UC) y los buffers/entornos asociados con cada una de estas áreas, estados, municipios y cuencas hidrográficas de la Amazonía Legal.
Las relaciones entre las entidades se dan según el siguiente diagrama:
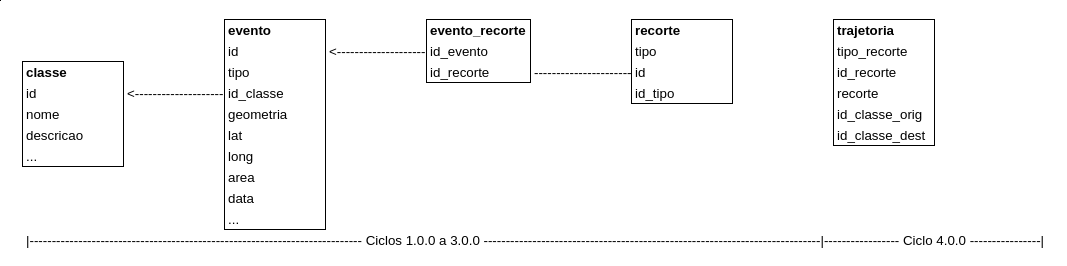
donde:
evento puede ser un evento DETER, foco de calor, etc., que contiene un campo geoespacial – polígono o punto –, área (cuando corresponda) y referencia a clase de evento (equivalente a la clase de DETER) y municipio de ocurrencia.
clase representa un elemento de una biblioteca de clases.
recorte es la entidad geoespacial (TI, UC, QUI, CAR, municipio, UF, etc.) donde tienen lugar los eventos, y que se puede vincular a otras bases de datos y tablas dedicadas a estas entidades a través de los campos recorte.tipo y recorte.id_tipo.
La abstracción realizada en el modelo de datos para las entidades evento y territorio permite manejar una serie de conjuntos de datos uniformemente, lo que consolida rutinas de cruce y análisis y también facilita la importación de nuevos conjuntos, como se ejemplifica en el diagrama a continuación:
PRODES --.
\
SAD ----.
\
DETER ---------> Eventos
´
Tablero de la Amazonía -----´
´
FIRMS ---´
Geo ISA (ARP) --.
\
IBGE ------> Territorios
´
INCRA --´
E1.2 - Modelo de la base de datos¶
Mientras el modelo de entidades y relaciones ofrece una vista de nivel más alto para la forma de los conjuntos de datos, el modelo de la base de datos indica cómo, en la práctica, se almacenarán las entidades con vistas a la optimización de consultas.
E1.3.1 Presupuestos del modelado¶
Se asumieron los siguientes supuestos para la creación del modelo de la base de datos:
En un futuro cercano es posible que se produzca un incremento considerable de eventos de presión y amenaza, lo que implica grandes conjuntos de datos a incorporar;
La creación de nuevos balances y cruces debe ser simple hasta el punto de no requerir remodelación de la base de datos;
El sistema debe tener un rendimiento suficiente para realizar selecciones arbitrarias sin un tiempo de espera muy largo.
E1.3.2 - Bases canónicas y derivadas¶
Para satisfacer estos requisitos, se han considerado datos en tres modalidades:
Dato bruto: es el obtenido de la fuente, por ejemplo, archivo zip, shapefile, etc., cuyo almacenamiento se produce según la disponibilidad de espacio y para fines de conferencia, salvaguardia y usos futuros;
Base de datos canónica: donde los eventos y recortes siguen sus estructuras originales y son actualizados solo por la institución de origen (autor/autoridad), sirviendo como dato de referencia tanto para los propósitos de esta especificación como para salvaguardia de datos y usos futuros. Algunas bases canónicas que ya existen en bancos corporativos de ISA incluyen los Focos de Calor (INPE) y la Violencia (SisArp / CIMI); tales bases se podrán utilizar en futuros ciclos del Panel;
Base de datos derivada: los balances se calculan a partir de los datos canónicos y se almacenan en estructuras derivadas, que son estructuras renormalizadas, para optimizar consultas. Los datos derivados, hasta cierto punto, son datos redundantes de los datos canónicos, es decir, pueden ser copias de los datos canónicos en estructuras más aptas para el consumo final o incluso el resultado de los cálculos realizados a partir de lo datos canónicos.
E1.3.3 - Segmentación y partición¶
Para optimizar las consultas, se estableció que tablas derivadas de eventos fuesen segmentadas o partidas por:
Tipo de evento;
Recorte;
Rango de periodo o fecha.
Dependiendo de la conveniencia y necesidad, las tablas derivadas también pueden ser renormalizadas.
Nota I: Se recomienda evaluar a lo largo de la implementación si la segmentación, partición y desnormalización deben realizarse para todos los eventos, lo que se puede hacer, según sea necesario, en tipos de eventos con muchas ocurrencias. Sin embargo, la adopción de una acción uniforme y escalable puede reducir la cantidad de código, ya que de esta manera se evitan las excepciones a la regla.
Nota II: Se recomienda realizar particiones por fecha y segmentación por tipo de evento y recorte. La partición por fecha se implementa utilizando la funcionalidad respectiva del PostgreSQL, mientras la segmentación se implementa con la simple creación de tablas de eventos según el tipo de evento y recorte.
E1.4 - Etapas de incrustación¶
Para las etapas de incrustación, se consideraron las siguientes alternativas:
E1.4.1 - (Alternativa 1) Calcular y compilar¶
Descarga de datos brutos: el conjunto de datos se obtiene de la fuente y en su estado bruto;
Importación: datos canónicos se importan en el formato tal como se disponen en la fuente de origen; se realizan rectificaciones y validaciones de datos solo para corrección de errores, comprobaciones y conversiones de formato;
Cálculo de balances: cruce de datos canónicos de eventos y recortes y almacenamiento del resultado en estructuras derivadas sin segmentación / partición / renormalización;
Compilación: se segmentan / particionan / renormalizan los balances para optimizar las consultas dinámicas.
E1.4.2 - (Alternativa 2) Compilar y calcular¶
Descarga de datos brutos: el conjunto de datos se obtiene de la fuente y en su estado bruto;
Importación: datos canónicos se importan en el formato tal como se disponen en la fuente de origen; se realizan rectificaciones y validaciones de datos solo para corrección de errores, comprobaciones y conversiones de formato;
Compilación: se segmentan / particionan / renormalizan para optimizar los cálculos y las consultas dinámicas;
Cálculo de balances: cruce de datos compilados de eventos y recortes y almacenamiento del resultado en estructuras derivadas.
E1.4.3 - (Alternativa 3) Segmentar y calcular¶
Descarga de datos brutos: el conjunto de datos se obtiene de la fuente y en su estado bruto;
Importación: datos canónicos se importan en el formato tal como se disponen en la fuente; se realizan rectificaciones y validaciones de datos solo para corrección de errores, comprobaciones y conversiones de formato;
Cálculo de balances: cruce de eventos y recortes y almacenamiento del resultado en estructuras derivadas, modeladas con segmentación por tipo de evento y recorte y partición por fecha.
E1.4.4 - (Alternativa 4) Particionar, segmentar, calcular¶
Descarga de datos brutos: el conjunto de datos se obtiene de la fuente y en su estado bruto;
Importación: los datos brutos se canonizan, es decir, se importan en el formato tal como lo proporciona la fuente (datos brutos) y, opcionalmente, particionados por fecha; rectificaciones y validaciones se hacen solo para validación, corrección de errores, verificaciones y conversión de formatos, por ejemplo, para corregir las fechas;
Cálculo de balances: cruce de eventos y recortes y almacenamiento del resultado en estructuras derivadas, modeladas con segmentación por tipo de evento y recorte y, opcionalmente, con partición por fecha – tarea realizada por la Biblioteca de Descarga e Incrustación;
Compilación: opcionalmente y si es necesario, los cálculos se pueden segmentar / partir / renormalizar para optimizar las consultas dinámicas – tarea realizada por la Biblioteca de Análisis (API).
A continuación, se incluye una breve descripción de los pros y los contras de cada optimización.
Compilación: La Alternativa 1 facilita la codificación de los balances, pero puede causar reelaboración en el paso de compilación, es decir, requiere más consultas a la base y código adicional. Por otro lado, la compilación anterior a la codificación de los balances (Alternativa 2) puede convertir el cruce de datos en una tarea bastante compleja, ya que el propósito de la compilación es reducir el acceso a la base de datos a través de la generación de contenido en la estructura utilizada por la aplicación frontend (caché del Panel). En general, se recomienda que los datos almacenados en la caché del frontend se compilen solo cuando sea necesario, priorizando a la caché de datos sin compilación.
Partición: Mientras la partición por fecha puede implicar un incremento de rendimiento en el acceso a los datos durante los cálculos y otras consultas, es posible también dificulte los cálculos debido a la limitación del uso de claves externas en la tablas, si es de PostgreSQL. Esto puede ser un factor limitante en el caso de cruce de informaciones relacionadas entre tablas, pero no debería ser un problema en el caso de cruces geoespaciales.
Segmentación: Como la cantidad de recortes tiende a ser mucho menor que la cantidad de eventos, se recomienda la segmentación de los últimos. La segmentación puede reducir el tamaño de las tablas y mantener los eventos separados por recorte de forma predeterminada, pero esta opción hace que cualquier relación entre dos tipos de recortes distintos requieran consultas JOIN. Otra posibilidad es hacer uso de la subpartición en lugar de la segmentación, pero eso puede agregar muchos niveles de complejidad en el mantenimiento de la base de datos.
Abordaje elegido¶
Durante la implementación se evaluaron todas las alternativas, pero se optó por el siguiente enfoque en vista de una solución genérica, escalable y sin muchas excepciones en el manejo de los datos:
Se implementó un flujo de incrustación de tipo ELT (Extract, Load, Transform), donde los datos canónicos se descargan, luego se cargan en la base de datos y por fin se convierten al modelo de datos adoptado;
En el paso de la conversión, se produjeron tanto el cálculo de los balances como la compilaciones para optimizar las consultas;
Se optó por la partición por tipo de evento;
Se realizaron varias optimizaciones de la base de datos, como indexar y evitar la fragmentación de los datos ingresados, ordenando los eventos por fecha al incluirlos en las tablas.
E1.5 - Frecuencia¶
Durante las evaluaciones preliminares, se consideró las siguientes posibilidades de selección de rangos de tiempo:
Selección arbitraria;
División obligatoria a intervalos fijos (mensual, anual, etc.).
Opciones de alcance del conjunto de datos:
Integral: los conjuntos de datos se ubican entre la fecha más antigua y la más reciente;
Parcial: no se utilizan datos muy antiguos debido a la disponibilidad de recursos informáticos.
Se consideró la velocidad para consultas (queries) a la base de datos y el espacio de almacenamiento disponible para el uso de la selección arbitraria de fechas.
E2 - Subsistema de descarga e incrustación («importer»)¶
El subsistema importer de Alertas+ es responsable de las rutinas de importación y
cruce de datos.
E2.1 - Requisitos¶
Dicho subsistema de recopilación de conjuntos de datos se divide en diferentes
importers (importadores), cada uno responsable por:
Descargar los conjuntos de datos brutos desde el endpoint de disponibilidad del conjunto de datos;
Incrustar los conjuntos de datos descargados en bases de datos tabular y geoespacial (datos canónicos y derivados);
Ejecutarse de forma periódica y automática, trabajando tanto para la alimentación de bases de datos vacías (sin datos) como para la actualización de bases de datos existentes;
Ejecutarse en el sistema operativo GNU / Linux sin interfaz gráfica, por ejemplo, en un cronjob;
Ser compatible con el modelo de datos especificado en este documento.
Por lo tanto, depende de cada importador no solo descargar los datos brutos, sino también la incrustación en las bases de datos canónicas y derivadas según el modelado elegido. Para ello, es necesario que el modelado realice el cruce de los eventos con los recortes durante el proceso de inclusión de datos en las bases.
E2.2 - Flujo de incrustación¶
El flujo de incrustación de datos debe ser una rutina estática (generar datos que quedan almacenados), automática (ejecutarse sin intervención manual) y periódica (correr con una frecuencia por definir), y debe estar de acuerdo con el siguiente diagrama:
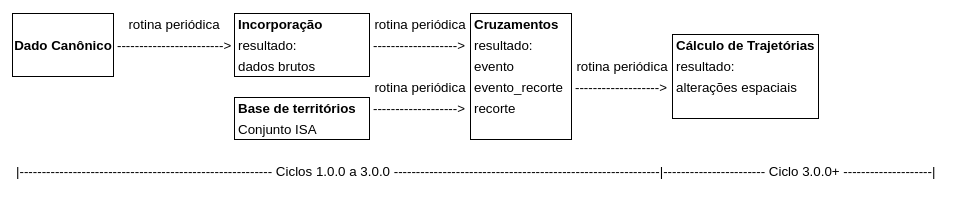
Los cruces se producen en el encuentro entre los datos del evento y los datos de bases existentes sobre los recortes geoespaciales, siempre según el modelado de datos discutido en el ítem E1.2.
El subsistema de importación tiene scripts y bibliotecas genéricas que reducen bastante la cantidad de código necesaria para cada importador. Además, cuida de la creación de metadatos de importación consumidos por el panel de consulta.
Los resultados se calculan para cada área protegida y tipo de evento (deforestación, quema), lo que permite la visualización de las áreas protegidas de forma individuada.
La mayoría de los importadores adopta el pipeline Extract, Load and Transform (ELT), pero otras líneas son compatibles, como Extract, Transform, Load (ETL) o incluso algo más simple como LT (Load, Transform).
Las rutinas de la etapa de conversión se dividen en «operaciones» que realizan tareas específicas de cruce y análisis.
E2.3 - Desglose de clases DETER¶
En el caso específico de DETER, las clases mapeadas por rango de períodos arbitrarios se alterará en relación con las clases canónicas proporcionadas por el INPE.
El esquema de clases canónicas se describe en la siguiente tabla:
| Clase nivel 1 | Clase nivel 2 |
|---|---|
| Deforestación | deforestación con suelo expuesto |
| deforestación con vegetación | |
| minería. | |
| ----------------------- | -------------------------------------- |
| Degradación | degradación |
| cicatriz de incendio | |
| ----------------------- | -------------------------------------- |
| Explotación de madera | tala selectiva tipo 1 (desordenado) |
| tala selectiva tipo 2 (geométrico) |
Sin embargo, Alertas+ utiliza la siguiente clasificación:
| Clase nivel 1 | Clase nivel 2 |
|---|---|
| Deforestación | deforestación con suelo expuesto |
| deforestación con vegetación | |
| ---------------- | --------------------------------------------- |
| Minería | área minada |
| ---------------- | --------------------------------------------- |
| Quema | cicatriz de incendio |
| ---------------- | --------------------------------------------- |
| Degradación | degradación |
| tala selectiva tipo 1 (desordenado) | |
| tala selectiva tipo 2 (geométrico) |
Motivo:
Esta categorización ayuda a comparar eventos de focos de calor de manera más explícita con los datos DETER, desglosando la importancia y los efectos de los incendios;
Permite aislar las cicatrices de incendio para correlacionarlas con otras fuentes de focos de calor;
Los eventos en la categoría «degradación» generalmente preceden a la deforestación, y pueden o no resultar en una deforestación de tala rasa;
El fuego puede ser parte del proceso de deforestación o no;
La individuación de la categoría «minería» permite análisis específicos sobre este tipo de presión / amenaza a las áreas protegidas.
Ejemplos:
En el PIX (Parque Indígena Xingu) hay cicatrices de incendio, pero poca deforestación o degradación forestal.
La degradación puede estar asociada con el comienzo de la deforestación de tala rasa;
Los invasores ocupan un área y queman la vegetación debajo del dosel del bosque;
Después de la quema o remoción de árboles del sotobosque, las actividades de deforestación pueden implicar la eliminación de árboles más grandes a través de motosierra o el uso de maquinaria agrícola si el terreno no tiene árboles de interés económico.
En el sur de la Amazonía, en la transición al bioma Cerrado, ocurren incendios no relacionado con los procesos de deforestación, sino más bien con la práctica de manejo del paisaje o de los sistemas agrícolas (como quemas que se escapan de las haciendas y pueden convertirse en incendios forestales de grandes extensiones).
También cabe destacar que, en el eventual caso de incrustación de datos DETER Cerrado, este es un dato sin división de clases, es decir, todos los eventos se refieren a alertas de deforestación por tala rasa y, por lo tanto, se clasifican así en la rutina de importación. Cuando se hace esto, los dos conjuntos de datos se vuelven compatibles (de Amazonía Legal y el bioma Cerrado), lo que permite una selección única en la interfaz ya que ambos comparten el mismo tipo de evento.
Para obtener información actualizada sobre la definición de clases DETER, consulte el config.py del respectivo importador.
E2.4 - Desglose de las clases de otros tipos de eventos¶
Para otros tipos de eventos, se utilizó la definición canónica de clases y, en la ausencia de ella, se realizó una clasificación según la cobertura vegetal existente en el lugar y fecha del evento.
La información más actualizada sobre la definición de clases se encuentra en los archivos
config.py de cada importador. La siguiente lista es solo un ejemplo de
las clases de nivel 1.
Para eventos de incendio del Tablero de la Amazonía:
Nivel 1: se refiere al tipo de fuego:
1: Sabana y pastizales (savanna and grassland);
2: Pequeños desmontes y agricultura (small clearing and agriculture);
3: Sotobosque (understory);
4: Incendios de deforestación (deforestation fires).
Para puntos de incendios activos FIRMS:
Clases determinadas por la cobertura vegetal en la ubicación de la ocurrencia, según la colección 5 de MapBiomas (https://mapbiomas.org/colecao-5) y de acuerdo a la cobertura vegetal a la fecha del evento.
Para la deforestación PRODES:
Nivel 1: clase única (deforestación).
Para alertas de deforestación y degradación SAD:
Nivel 1:
1: Deforestación;
2: Degradación.
E3 - Subsistemas de análisis («query» y «API»)¶
El papel de los subsistemas de análisis es producir balances analíticos sobre los datos recopilados, funcionando como una rutina dinámica (calcula y devuelve datos sin almacenarlos en bancos), automática (no requiere intervención manual para realizarse) y aperiódica (opera según lo soliciten).
E3.1 - Flujo de análisis¶
El cálculo de los análisis se representa según el diagrama de interacción secuencial a continuación:

La producción de los análisis se obtendrá a través de llamadas realizadas desde un frontend dirigido a una API, que realizará consultas dinámicas (queries) en las bases de datos discutidas en la sección E1.2.
Todos los análisis siguientes se consideran a partir del modelo propuesto en la sección Modelado de Datos, para que en el futuro sea posible reutilizar fácilmente las rutinas desarrolladas en nuevos conjuntos de datos (eventos y clases).
E4 - Shapefile de áreas protegidas mantenidos por ISA¶
Las áreas protegidas (Tierras Indígenas y Unidades de Conservación) en la Amazonía Legal se han digitalizado en un entorno GIS (Sistema de Información Geográfica) basado en los memoriales descriptivos de documentos oficiales para la creación o alteración del perímetro. Las áreas se trazan a una escala de 1 : 100.000. Para las Unidades de Conservación Estatales, adoptamos las bases de datos de ICMBio / MMA como referencia para los datos espaciales, complementadas con información de las agencias estatales del SISNAMA. Cuando no hay un memorial descriptivo del área protegida o si tiene errores que impidan el trazado del perímetro, se ha utilizado los datos vectoriales y matriciales obtenidos de agencias oficiales federales y estatales (como FUNAI, MMA y secretarías estatales) para revisión o complementación, así como documentos no cartográficos, por ejemplo, planes de gestión de las Unidades de Conservación.
Los datos espaciales de municipios y estados utilizados como referencia para el trazado de las áreas protegidas se toman tanto de SIVAM (Sistema de Vigilância da Amazônia, 2004), en la escala de 250 mil, como de la base cartográfica continua para Brasil, en la escala de 250 mil (IBGE, 2015). Además de estas bases oficiales, los rásteres globales (como Google) y las imágenes satelitales de la serie Landsat también han ayudado en el proceso de construcción de los límites si existen limitaciones en los datos vectoriales.
Todos los elementos han sido convertidos al sistema de coordenadas geográficas y referenciados a Datum Sirgas 2000.
E5 - Buffers y capas¶
Actualmente, y para un ARP individual, el recuento de eventos se calcula dentro de la unidad espacial y en tres buffers simples:
De 0 a 3 km: procedente de la normativa sobre UC (aplicado a las TI para compatibilidad);
De 3 a 10 km: valor arbitrario;
De 0 a 10 km (suma de los buffers 1 y 2): valor arbitrario.
Se delimitaron los datos espaciales referentes a zonas de amortiguamiento en áreas protegidas en un entorno GIS a partir de la función buffer.
Para ciclos de desarrollo posteriores, se pueden considerar otras posibilidades de buffers con criterios más complejos, incluidos aquellos «en las ARP».
En el caso de conjuntos de datos que se extienden más allá de la Amazonía Legal brasileña, se aplica una capa para limitar el conjunto derivado de eventos a solo aquellos que ocurren en la Amazonía Legal.
E6 - Salidas analíticas¶
Los períodos de análisis son arbitrarios y se delimitan por fechas de comienzo y fin, pero también pueden representar períodos definidos, como diario, quincenal, mensual, anual y total.
Las salidas del Panel que integran los datos reúnen los siguientes resultados:
Área total (y por clases de nivel 1) de alertas DETER (anuales, mensuales y acumulado) en los siguientes recortes espaciales: Tierras Indígenas, Unidades de Conservación, buffer ARP de 3 km y buffer ARP de 10 km, municipios (MUN), Unidades de la Federación y cuencas hidrográficas;
Los resultados traen el historial de ocurrencia en cada unidad territorial, incluso en las zonas de amortiguamiento, dentro del límite de la Amazonía Legal brasileña, que puede acumularse históricamente, anualmente, mensualmente o en cualquier otro balance necesario;
Las Áreas de Protección Ambiental (APA) se pueden seleccionar por separado, es decir, en separado del conjunto de UC;
Ocurrencia de superposición entre deforestación en diferentes períodos. En estos casos, es necesario realizar una contabilidad y eventualmente confirmar la información con los equipos técnicos responsables de cada conjunto de datos para comprender la metodología y la razón de la ocurrencia de estos casos, tal vez como un control de calidad de los datos.
Para ciclos de desarrollo futuros, los siguientes análisis pueden ser considerados y son compatibles con el modelo de datos adoptado:
Cambio de la geometría / clase a lo largo del tiempo, en respuesta al siguiente interrogante: ¿Cuáles son las trayectorias de las clases de eventos (nivel 1 y 2)? El Panel podría presentar lo que sucedió en un período dado (libre elección) por unidad geográfica (TI o UC). Un ejemplo de esto es la plataforma MapBiomas, que presenta la evolución entre dos distintos períodos de cambio de clase. En este panel de alertas, estarían representados los cambios que ocurren entre las clases 1 y 2;
Modificaciones a lo largo del tiempo en el área de cada clase como resultado de la dinámica del proceso de deforestación, en respuesta al siguiente interrogante: ¿Cuánto de los eventos (clase “degradación” o “explotación de madera”) se convirtieron en eventos (polígonos) de la clase “deforestación”?
E7 - Panel de consulta¶
El panel de consulta de Alertas+ contiene:
Conjuntos de datos disponibles sobre deforestación y degradación forestal;
Tipología de territorios: áreas protegidas, buffer correspondiente, estados y municipios;
Selectores específicos para la elección de áreas protegidas, estados, municipios y cuencas hidrográficas;
Selector de marco de tiempo: fecha de inicio y fecha de finalización;
Selector de escala de tiempo para los resultados: anual, mensual y cuatrimestral;
Selector de visualización de unidades espaciales en el gráfico: 5, 10 o 20 unidades;
Interfaz con herramienta para comparar recortes espaciales, fechas y fuentes de alertas.
E8 - Alcance¶
Primera versión pública: Amazonía Legal brasileña, con selección restringida a los municipios presentes en este recorte.
Versiones posteriores: pueden presentar mayor alcance, posiblemente incluido el bioma Cerrado y otras regiones.
En el caso de los conjuntos INPE, se observó que actualmente TerraBrasilis ofrece los conjuntos para Amazonía Legal y el bioma Cerrado. Hay superposición entre ambos conjuntos, ya que parte de la Amazonía Legal se sobrepone al bioma Cerrado.
Es posible que INPE utilice en este caso la misma lógica que PRODES: mapea fragmentos de bosque en el bioma Cerrado y, a partir de un análisis espacial, verifica la superposición entre los polígonos.
En ciclos posteriores será necesario adaptar la rutina de importación de datos canónicos para excluir esta duplicidad, por ejemplo, separando lo que se refiere a la Amazonía Legal de las informaciones sobre el bioma Cerrado. Pero hay que tomar en cuenta que este último no tiene una variedad de clases mapeadas, es decir, hay solamente «advertencias de deforestación», mientras que en el primero tenemos más clases (deforestación de tala rasa, quemas, minería, etc.).
E9 - Cuencas hidrográficas¶
Se utilizó una base de datos canónica de ANA con revisiones realizadas por ISA, lo que resultó en una base de cuencas hidrográficas derivada que incluye ajustes de las cuencas del Río Negro y Xingu.
Los datos canónicos tienen inconsistencias debido al relieve y problemas metodológicos que traen consecuencias a nivel de resolución para el trabajo que realiza ISA en estas dos regiones.
Así, se realizaron mejoras e incluso ajustes manuales para corregir situaciones en que la cuenca hidrográfica terminaba antes de su propia desembocadura. Numéricamente, la cuenca hidrográfica resultante no es muy diferente, pero sí lo es en términos de diseño y forma.
En Alertas+ se utiliza el nivel 2 de las cuencas hidrográficas de este conjunto.
La forma de incrustación de las cuencas difiere de otros recortes territoriales, algo que se menciona en la sección «Supuestos, características y limitaciones».
E10 - Estimación de emisiones de dióxido de carbono¶
Alertas+ dispone de una operación de estimación de emisiones de dióxido de carbono asociadas con los eventos.
Esta salida está implementada pero se encuentra en una fase experimental de análisis, comparación con otras estimaciones y calibración de parámetros de emisiones, así que todavía no se recomienda su uso.
La interfaz de consulta de Alertas+ ya tiene la contabilidad del impacto causado por los eventos analizados por el usuario, y proporciona el equivalente en dióxido de carbono emitido, pero esta función está actualmente deshabilitada, a la espera de homologación final.
A pesar de la indisponibilidad de estos datos en el panel de consulta y la recomendación para que aún no se utilicen, dicha información ya se calcula en la rutina del sistema, estando disponible para consumo vía API y a disposición para calcularse de forma independiente a través del código fuente de Alertas+ y archivos de entrada (mapa de biomasa, mapa de cobertura vegetal y los conjuntos de eventos).
Los supuestos involucrados en estas estimaciones se analizan con más detalle en la sección «Supuestos, características y limitaciones», mientras la presente sección busca explicar en líneas generales los algoritmos de cálculo y en qué referencias teóricas y metodológicas se basan.
El cálculo de las emisiones se basa en dos factores:
Tipo de evento;
Contenido de dióxido de carbono presente en el lugar que ocurrió el evento correspondiente al polígono o, para eventos puntuales, sobre la cobertura vegetal del punto correspondiente a la fecha de ocurrencia del evento.
El sistema tiene una operación para calcular el dióxido de carbono emitido por cada evento registrado. Para optimizar el tiempo de respuesta del sistema, el factor de emisión asociado con cada evento se calcula de antemano.
El método para estimar las emisiones de dióxido de carbono es diferente para eventos poligonales y eventos puntuales (focos de calor), que se tratan en las secciones a continuación.
Cálculo para el caso poligonal¶
Tipo de evento. En eventos poligonales, la emisión asociada con los eventos de tala rasa será el 100 % del carbono asociado con el polígono. En los polígonos de degradación, la proporción será menor. El índice de emisión de las clases de áreas quemadas y degradadas será del 57 % y el 35 %, basado en la investigación de Berenguer et al., 2014 (A Large-Scale Field Assessment of Carbon Stocks in Human-Modified Tropical Forests).
Este monto se calcula mediante una operación de integración de un dato matricial que representa, con suficiente resolución, el contenido de dióxido de carbono por hectárea (ha) en el área cubierta por el sistema. En concreto, el mapa de carbono utilizado fue desarrollado por ESA Biomass Climate Change Initiative.
El valor de la densidad de la biomasa se extrae en el pretratamiento, a partir de un ráster de resolución de 100 metros desarrollado por ESA, y que es la fuente de biomasa más fiable (según varios expertos):
Para realizar el cálculo, se multiplica el valor de emisión (ha) por el área de eventos poligonales. Para evitar el doble recuento, este cálculo se hace usando la función
smart_emissions, que calcula el área de los polígonos que se superponen y la multiplica por el promedio de la densidad de emisión precalculada de estos polígonos. Para los polígonos que no presentan superposición, el cálculo se realiza a través de la simple suma de la emisión individual, calculada por la multiplicación del área del polígono por la densidad de emisión precalculada.
De esta manera, para los polígonos de DETER, SAD, PRODES y del Tablero de la Amazonía, por ejemplo, la emisión de dióxido de carbono se calcula multiplicando el valor de densidad de la biomasa en el sitio del evento (centroide poligonal), en MgC / ha, por el área poligonal y factor de conversión de biomasa (1 para deforestación, 0,57 para incendios y 0,35 para degradación). Estos valores se tomaron de Berenguer et al. (2014).
Cálculo para el caso puntual¶
Tipo de evento. Los eventos puntuales de fuego hacen referencia al valor de FRP (Fire Radiative Power), conforme la investigación inicial de Wooster (2002). Este valor se multiplica por un factor de conversión medio para emisiones de Dióxido de Carbono Equivalente, conforme el informe de Kaiser (2012), que suele ser
39.71 * 1.39 = 55.20para obtener toneladas de dióxido de carbono equivalente emitidas por cada foco detectado.Sin embargo, para obtener una estimación más precisa, se adoptó un procedimiento más elaborado, que consta de los siguientes pasos adicionales:
Operación en hoja de cálculo de los factores de emisión por cobertura del suelo;
Elaboración de mapas anuales de cobertura del suelo con base en la Colección 5 de MapBiomas que utiliza Google Earth Engine.
El balance final del dióxido de carbono emitido se realiza mediante la simple suma de la emisión correspondiente a cada evento, en el caso de focos de calor.
Para datos puntuales – por ejemplo, focos de calor FIRMS –, el cálculo de la emisión de dióxido de carbono de los incendios es un tema de investigación importante en la ciencias ambientales.
En el presente desarrollo, se estudiaron las referencias clásicas (especialmente Kaiser et al., 2012) para determinar la relación entre la potencia del fuego (el parámetro FRP disponible para cada evento) y la emisión de carbono asociada.
Otras referencias bibliográficas y consultas con investigadores de INPE resultaron en la definición de un factor promedio de 55.20 Mg / W, es decir, la emisión de dióxido de carbono bruta diaria de una fuente de calor activa, en toneladas, equivale a 55,2 veces el FRP.
Aun así, se consideró necesario:
Preparar un ráster con las varias capas – una para cada año desde 1984 – de cobertura vegetal;
Clasificar los eventos de focos de fuego según la cobertura del suelo referente al año de ocurrencia del brote;
Calcular los factores de emisión según las coberturas del suelo seleccionadas de la Colección 5 de MapBiomas.
Los factores de emisión se definen para cada importación en su archivo
de configuración config.py, lo que permite realizar cálculos de emisiones
calibrados y de manera fácil.
Gestión de superposiciones¶
El tratamiento de las superposiciones resultó gran dificultad en la implementación:
El problema: a la hora de calcular la emisión total asociada con una solicitud del usuario, los valores de emisión de cada evento se suman para entregar el valor total. El problema surge cuando hay superposición de eventos seleccionados. Por ejemplo, si el usuario quiere las emisiones totales en zonas de amortiguamiento de TI, dichos buffers pueden superponerse en el caso de TI contiguas, con lo que los eventos asociados se duplican total o parcialmente. Puede también que sea el caso de una selección de TI y UC que se superponen.
La solución: la forma más precisa de calcular estas emisiones sería disolver estos polígonos (
ST_Union), recortar (clipar) el ráster de biomasa y calcular la biomasa total asociada con este recorte (clip). Desafortunadamente este procesamiento lleva horas, lo que lo hace inviable para esta propuesta de panel. Otra posibilidad sería convertir cada polígono en un prisma, con una altura equivalente a la densidad de biomasa, y en tiempo de ejecución hacer una disolución y un cálculo de volumen en tres dimensiones. Esta opción también resultó ser muy lenta y impracticable.Como solución adoptada, se realizó la separación de polígonos que no se superponen y los que sí. A partir de esta división se puede calcular la emisión correspondiente al primero grupo de forma sencilla, sumando las emisiones a las características del polígono. En el caso de los polígonos superpuestos se realiza un proceso diferente, se disuelve el área y se calcula el valor promedio de las emisiones por hectárea. Luego, este valor promedio se multiplica por el área total disuelta.
Estimamos que el error asociado con esta simplificación no es muy grande, hasta porque la proporción de superposiciones es baja (entre el 5 % y 10 %) si no se consideran los buffers. Para los análisis que incorporan buffers, el error puede ser mayor, pero creemos que el error asociado es mucho menor que el error asociado con otros parámetros del cálculo.
Los factores de emisión para cada tipo de evento se registran en los archivos de configuración correspondientes:
En el caso de eventos de tipo poligonal, el factor se refiere a MgCe / ha;
En caso de eventos puntuales, la unidad del factor es MgCe / MJ.
Procedimiento para generar el mapa de biomasa¶
Para generar el mapa de carbono (biomasa), se realizó el siguiente procedimiento manual:
Descarga de los archivos GeoTIFF proporcionados por ESA Biomass Climate Change Initiative;
Ensamblaje de los mapas de GeoTIFF en QGIS para crear un solo ráster;
Recorte del área de interés;
Conversión a una query SQL importable.
Dicho mapa de biomasa se encuentra disponible en la página de descargas de Alertas+.
Referencias¶
E. Berenguer et al. (2014) A Large-Scale Field Assessment of Carbon Stocks in Human-Modified Tropical Forests, DOI 10.1111/gcb.12627.
J.W. Kaiser et al. (2012) Biomass Burning Emissions Estimated with a Global Fire Assimilation System Based on Observed Fire Radiative Power, DOI 10.5194/bg-9-527-2012.
E11 - Formatos y dinámica de salida de datos¶
Para la producción de mapas y otros análisis por plataformas web, los resultados obtenidos deben organizarse para estar disponibles en los siguientes formatos:
Formato estructurado abierto (CSV, JSON y GeoJSON);
Formato vectorial (shapefile);
Formato bruto (tabla SQL o ráster);
Interacción vía servicios web (API RESTful);
Tiles para consumo dinámico (Tile Server en formato MVT - Mapbox Vector Tiles).
Los siguientes subsistemas se encargan de las salidas de datos:
Parte de las salidas se produce de forma dinámica (subsistemas de análisis «query» y «API»). La API del sistema se puede consultar de forma programática o interactiva, en el último caso a través de la página de API de Alertas+.
Otra parte, más estática, es producida por un subsistema de exportación («exporter»), disponible para su descarga en:
Uso directo del subsistema de importación, mediante el backend del sistema.
Los archivos estáticos se exportan automática y periódicamente desde el sistema, estando hoy restringidos a datos que no son eventos, como shapes de territorios y mapas de biomasa y cobertura vegetal.
Los datos de eventos se pueden obtener directamente de las fuentes canónicas.
E12 - Sistema de gestión operativa¶
Para monitorear y operar el sistema, especialmente para seguir los flujos de incrustación de datos y saber como responder a errores, Alertas+ tiene una instancia de Apache Airflow.
De igual manera, para las rutinas de mantenimiento periódico, cada importador tiene su propia rutina en Airflow, como se muestra en la siguiente imagen:

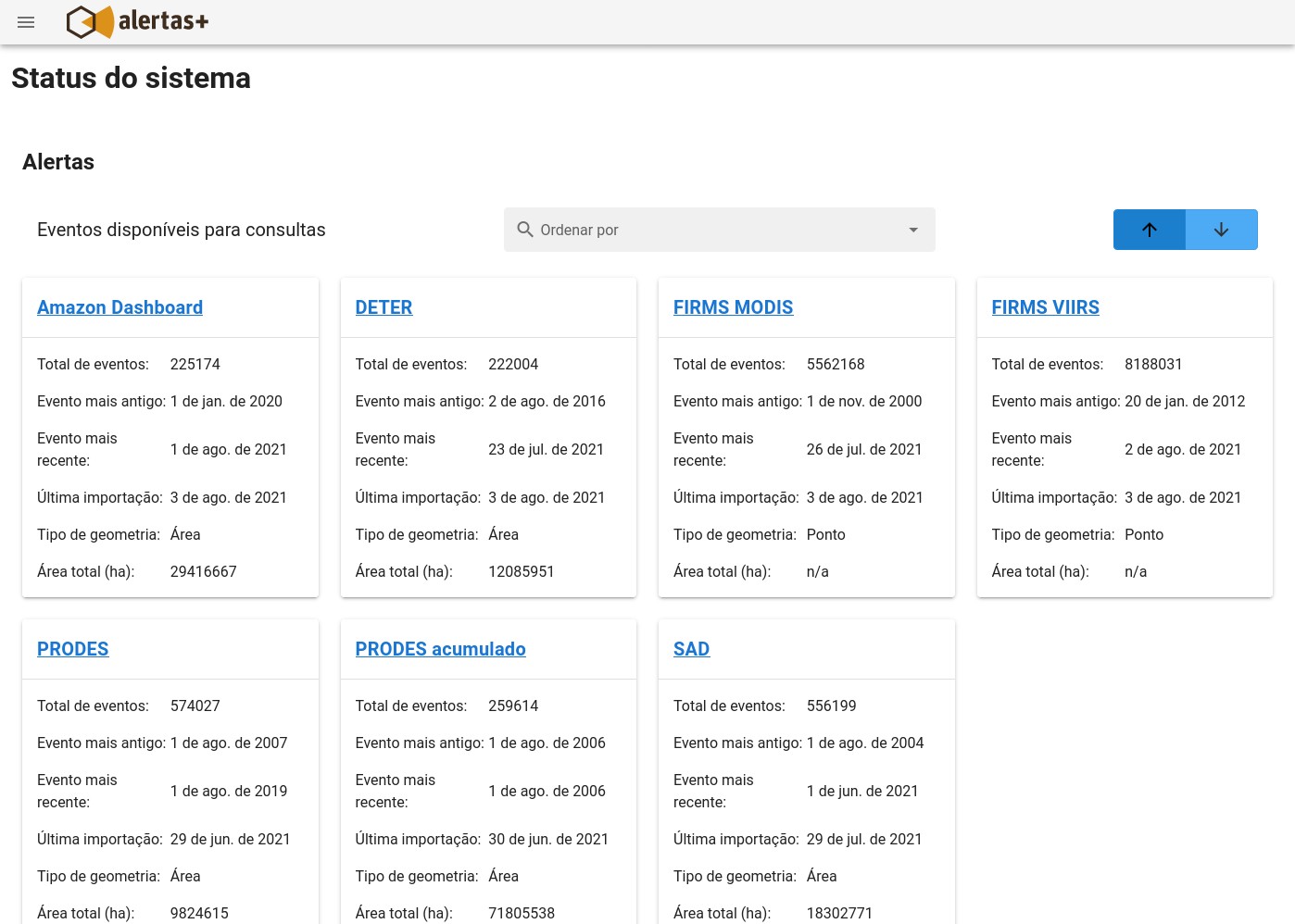
Alertas+ también tiene una página de estado de los datos pública, donde se reporta la condición más reciente de los conjuntos de datos:
Supuestos, características y limitaciones¶
En la construcción de Alertas+ se hizo un especial esfuerzo por documentar explícitamente y al máximo todos los supuestos y enfoques adoptados, no solo de los conjuntos de datos utilizados, sino también de las opciones de diseño e implementación.
Tales supuestos ayudaron a definir la aplicabilidad de Alertas+ como un sistema expeditivo de alertas casi en tiempo real.
Cuando fue posible, el proceso de homologación se utilizó para evaluar críticamente la validez de los supuestos.
Instantaneidad de los evento¶
El sistema asume que los eventos son instantáneos.
A diferencia de, por ejemplo, el Tablero de la Amazonía, Alertas+ no registra el inicio y el final de los eventos, como el inicio y el final de los incendios, tanto por la sencillez del modelo como para facilitar el uso de la interfaz, ya que no todos los conjuntos de datos tienen una fecha de finalización. Esa suposición funciona para el análisis de largos períodos, pero para intervalos cortos es imprecisa y falla, especialmente cuando el intervalo es más corto que la duración del evento.
Se supone que los eventos ocupan una sola fecha (escala diaria), pero el evento de hecho puede haber sido más corto o más largo. Esta suposición está implícita tanto en algunos conjuntos de datos (producto FRP de VIIRS y MODIS) como en el propio modelado de datos del Panel (evento en una fecha con día / mes / año); otros sistemas como el Tablero de la Amazonía consideran una fecha de inicio y finalización del incendio, mientras que este Panel considera solo una fecha (equivalente a la «start date» del Tablero de la Amazonía).
Fecha de los eventos¶
Para algunos conjuntos de datos, la fecha del evento se refiere a la fecha de detección y no a la fecha de ocurrencia, como es el caso de DETER y PRODES:
En DETER es especialmente relevante comprender la distinción entre el tiempo de
ocurrencia y el tiempo de detección. Un bosque se puede deforestar paso a paso,
pero su detección como tala rasa o área degradada solo ocurre
cuando las condiciones de observación por satélite son favorables. En DETER,
cada alerta de deforestación detectada en una imagen, y que no fue detectada
anteriormente, se considera nueva deforestación independientemente de la fecha
real de ocurrencia del evento.
Los datos DETER pueden incluir procesos de deforestación que ocurrieron en
períodos anteriores al mes de mapeo, cuya detección no haya sido
posible debido a limitaciones como la presencia de nube o la no disponibilidad de
imágenes. Por esta razón, es necesario distinguir entre el momento de ocurrencia y
la oportunidad de detección.
Esto se debe a que esta es una información basada en imágenes de los terrenos afectados que se obtienen periódicamente y no necesariamente cuando se produce la depredación de los bosques.
En otros tipos de eventos, como del Tablero de la Amazonía y FIRMS, la fecha de ocurrencia está más cerca del hecho porque se basan en la detección de fuego (focos de calor) en el paso periódico de satélites con sensores MODIS y VIIRS (este último de alta resolución).
Ausencia de procesos regenerativos¶
El sistema solo asume el proceso de degradación forestal y no estima tasas de regeneración en ningún nivel. Así, los valores acumulados en el Panel (deforestación, degradación forestal y emisiones de dióxido de carbono estimadas) pueden ser más grandes. Durante períodos prolongados esta diferencia puede ser significativa, mientras que en «tiempo casi real» («near real time») suele ser insignificante.
Temporalidad de las Áreas Protegidas¶
Todos los cálculos sobre Áreas Protegidas (ARP) las consideran dentro de su perímetro más reciente, es decir, el sistema no tiene en cuenta los eventos anteriores de las ARP o si existía o no en la fecha de registro de un evento.
Incluso, si se creó una ARP después de un evento, el sistema considera que lo mismo ocurrió en el área delimitada por la ARP.
A pesar de la simplificación que no considera la dimensión histórica del establecimiento y cambios en los límites de las ARP, el supuesto permite una consistencia analítica del historial de amenazas en el corte territorial.
Simplicidad de los buffers¶
Como se mencionó en la sección E4, el sistema actualmente incluye áreas del entorno (buffer) trazadas automáticamente para cada ARP.
Estos buffers simples no tienen en cuenta las superposiciones entre las ARP y entre buffers de ARP cercanas / superpuestas.
Para evitar el doble recuento de eventos y área afectada, las consultas a la base de datos del sistema tienen en cuenta dichas superposiciones a través de un proceso de precomputación de un algoritmo especial de «área inteligente» («smart area») para obtener los datos, sin contar dos veces, de forma ágil.
En el futuro se pueden considerar otros recortes de buffers, por ejemplo, aquellos que solo consideran la porción del territorio fuera de las ARP, es decir, sin superposición con otras ARP.
Estimaciones de emisiones de dióxido de carbono¶
Por lo general, se considera que todavía hay una serie de inexactitudes en todas las estimaciones de emisiones de dióxido de carbono, no solo de Alertas+.
La principal razón son las grandes incertidumbres en las estimaciones de reserva de carbono.
Aun así, creemos que se podrá utilizar las estimaciones de Alertas+ en un futuro próximo como indicadores generales de emisión en las áreas protegidas, a depender de una mejor calibración de algoritmos, eventuales mejoras en el mapa de biomasa y un proceso de homologación que pueda evaluar mejor las incertidumbres involucradas.
Aspectos metodológicos¶
Entre los aspectos metodológicos, la evaluación de algunos supuestos siguen pendientes:
Para los casos de tala rasa por quema total, se asume que el 100 % de la vegetación se emite a la atmósfera (coeficiente 1). ¿Qué tan fuerte es esta suposición?
Para el cálculo de emisiones en eventos de brotes:
Se asume implícitamente que el brote quemó con la misma potencia durante 24 horas. Puede que sea una premisa sólida que deba analizarse o no.
Se necesita confirmar si el FRP hoy contiene todas las correcciones aplicadas manualmente por Kaiser et al. (2012).
Se necesita confirmar la referencia experimental de la relación entre FRP y emisión presentada por Kaiser et al. (2012), por ejemplo, comprobando si hubo un experimento o mediciones en tierra junto con mediciones de satélite.
Fecha del mapa de biomasa¶
Al adoptar un mapa de dióxido de carbono / biomasa de 2018, se asume implícitamente la cobertura de 2018 como retroactiva a eventos anteriores a esta fecha.
Es decir, puede ser que el mapa indique menos presencia de dióxido de carbono si es utilizado para eventos que ocurrieron antes de 2018.
Además, es posible que desde 2018 hasta ahora estas áreas hayan sufrido alteraciones, es decir, haya ocurrido una pérdida que el sistema informa asociada con un determinado evento.
En resumen:
Las estimaciones anteriores a 2018 pueden ser conservadoras, pues que la biomasa reportada en 2018 en un determinado sitio puede ser menor que la biomasa existente en la fecha del evento.
Empero, las estimaciones posteriores a 2018 tienden a ser mejores.
Una posible solución sería utilizar también mapas más antiguos y calcular las pérdidas a partir del mapa más cercano a la fecha de interés.
Por lo general, las estimaciones de emisiones basadas en mapas de dióxido de carbono aún tienen grandes incertidumbres, especialmente porque estos mapas todavía se producen con vacilaciones, lo que debe mejorar en el futuro con disponibilidad de nuevos datos.
Deforestación PRODES y PRODES Acumulado¶
Al importar el conjunto de datos PRODES, los eventos se separaron en dos tipos:
Deforestación acumulada hasta 2007:
PRODES Acumulado;Deforestación anual a partir de 2008:
PRODES.
Vale la pena señalar que, en el caso de conjuntos de datos como PRODES, las fechas no se refieren a eventos reales, sino a valores anuales en cada recorte territorial.
La interfaz de búsqueda Alertas+ solo permite la selección anual de datos PRODES, y actualmente no permite la selección de datos PRODES Acumulado – que a pesar de esto se encuentran en la base de datos y se pueden utilizar en cálculos específicos de la deforestación total acumulada hasta la fecha reciente del conjunto.
Computación determinista, idempotencia y reversibilidad¶
El sistema Alertas+ es del tipo computación determinista, es decir, al ejecutar importaciones una y otra vez con el mismo conjunto de datos de entrada produce el mismo resultado.
Todos los importadores de datos tienen idempotencia, es decir, pueden ser ejecutados más de una vez y siempre producirán el mismo estado final de importación con el mismo conjunto de datos de entrada. Por supuesto, como los datos se actualizan en la fuente, el sistema tenderá a producir resultados también actualizados.
El sistema no es del tipo computación reversible, es decir, no hay procedimiento de reversión con los datos de salida que recuperen los datos de entrada. Esto puesto, la verificación de los datos para la homologación del sistema se ha realizado a través de una comparación paralela realizada manualmente por analistas de geoprocesamiento.
De la ausencia de eventos¶
La ausencia de eventos registrados no es evidencia de la ausencia de eventos ocurridos. Pueden producirse limitaciones en la detección de sistemas de sensores.
Aparte los falsos positivos, se puede suponer que la cantidad real de eventos es mayor que lo informado por el sistema debido a fallas en la detección de los datos utilizados, es decir, el sistema puede subestimar pero difícilmente sobrestimar las alertas.
Gestión de superposición de eventos¶
Algunos conjuntos requieren tratamiento para evitar la superposición entre eventos.
En el caso de DETER, las superposiciones no permitidas en el sistema son las de polígonos de clases que implican la eliminación total y definitiva de la cobertura forestal, que están representados por las categorías 1 (deforestación) y 2 (minería). Los polígonos de otras categorías pueden tener intersecciones internas (sería el caso, por ejemplo, de un lugar que sufre varias quemas sucesivas) o externas con polígonos de clase 1 o 2 (en el caso de un área que es primero quemada o degradada y luego deforestada).
Tratamiento de cuencas hidrográficas¶
Las cuencas hidrográficas no se identifican como un corte territorial adicional, sino de una manera especial.
Para evitar sobrecargar la base con nuevas intersecciones, el tratamiento
se hizo por medio de un JOIN espacial: en cada polígono o punto resultante de las
intersecciones de los eventos con los territorios se asigna una cuenca, en función de la
posición del punto o centroide.
Esto no trae inexactitudes significativas, debido a la diferencia de escala entre las
cuencas y eventos, y es mucho más rápido, ya que no sobrecarga el sistema
duplicando el tamaño de la tabla event_territory.
Dicha metodología tiene el problema de no tolerar la superposición entre polígonos en el shape de cuencas. Se aceptan vacíos pero no superposiciones.
Por lo tanto, y debido a la extensión geográfica de las cuencas hidrográficas, que supera en varios órdenes de magnitud al tamaño promedio de la deforestación y alertas integradas en el sistema, se propone realizar el cruce de eventos poligonales teniendo como referencia el centroide de cada polígono, lo que evitaría intersecciones en los propios polígonos.
Este cambio, que tiene un error mínimo asociado, puede además optimizar el rendimiento del sistema.
Se estima que siguiendo esta metodología el costo de integrar la nueva capa de análisis ha sido insignificante en términos de almacenamiento y rendimiento.
Agrupación temporal de resultados¶
El sistema admite la agregación temporal de eventos en escala diaria, semanal, mensual, cuatrimestral o anual («unidad temporal»).
En el caso de los conjuntos de escala anual (PRODES), los datos ya se han agregado anualmente en la fecha de inicio del período (01/08/2019 para el Año PRODES 2020, por ejemplo).
Para los conjuntos de escala mensual (SAD), no se admiten las agregaciones diarias y semanales.
La API del sistema tiene opciones para que la agregación de eventos ocurra al inicio o al final de cada período, en el caso de agregaciones semanales en adelante.
Comparación entre sistemas¶
Es importante tener en cuenta el recorte territorial en la interfaz de búsqueda de Alertas+ cuando se desee comparar los datos presentados por el sistema con los datos brutos de cada conjunto.
Cuando se realiza una selección, el total y el área de las alertas reportadas tienen en cuenta su superposición con el territorio seleccionado (intersección de los eventos con los territorios).
Esto se implementó a través de un desglose de eventos por territorio en la
tabla event_territory de la base de datos.
Para cada territorio donde haya una superposición con un evento, habrá una entrada en
event_territory para ese evento, pero con diferentes geometrías, proporcionadas por
la intersección del territorio con el evento. (Incluye más de un territorio.)
En consecuencia, lo que en algunos conjuntos de datos (como DETER) se llama advertencia / alerta / evento puede no ser exactamente el mismo evento reportado por Alertas+. Esto por la selección territorial elegida, que solo presentará la sección de la alerta que se cruza con los territorios elegidos.
Es decir, a depender de la selección realizada, la alerta de los datos originales se puede presentar solo en la parte que se cruza con el recorte territorial elegido, tanto en el polígono exhibido como en la cuantificación del área afectada.
En el caso de una selección más amplia (por ejemplo, todos los municipios o estados) habrá coincidencia en los informes, pues que no hay restricción territorial a aplicar.
Además, para evitar el doble recuento del números de eventos y área total, algunas de las opciones de selección están restringidas al consultar eventos:
La selección de cantidades de eventos tiene la restricción
DISTINCTen el ID del evento, para evitar la selección y el doble recuento de eventos;Los tipos de territorio
MUNyUFno se pueden seleccionar junto con otros tipos de territorio, porque el recuento de eventos (y posiblemente de áreas) se duplicarían – estos territorios siempre se superponen a las áreas protegidas y sus zonas de amortiguamiento (buffers).
Es decir, una alerta que originalmente cubría más de un territorio puede convertirse en N eventos durante el cruce (desagregación de eventos por territorio), pero NO SERÁN exhibidos por duplicado en las selecciones.
Por ejemplo, una alerta ambiental que cubre dos ARP se convierte en dos incidentes ambientales de área equivalente después del procesamiento de los datos canónicos.
La situación es análoga al caso de eventos puntuales, ya que pueden ocurrir en un lugar con superposición territorial.
Unidades de medida alternativas¶
En la interfaz de consulta Alertas+ es posible cambiar entre unidades de medida (kilómetros cuadrados, hectáreas, etc.), lo que está también disponible para expresión de áreas en:
Campos de fútbol, a través de la estandarización de CBF / FIFA, de
105 m x 68 m;Estimación de árboles maduros talados para el bioma amazónico, basada en artículo de Steege et al. (2003) A Spatial Model of Tree α-Diversity and Tree Density for the Amazon, que calcula la cantidad de árboles maduros por hectárea de bosque en pie entre 400 y 750; Alertas+ utiliza el promedio entre estos valores, o 575 árboles maduros por hectárea.
Dichos valores, a pesar de no aparecer en los sistemas de medición estándar, son de fácil comunicación y ayudan el público a comprender el impacto de los eventos de presión / amenaza.
Propósito general¶
El sistema tiene como finalidad el diagnóstico socioambiental y la incidencia en políticas públicas. Por esta razón, en su diseño no se tomó en cuenta solo la precisión científica, sino también la contundencia y agilidad del sistema.
Alertas+ no es un sistema con cálculos lentos y destinados a obtener resultados de precisión científica arbitraria o incluso forense, sino más bien es un sistema que produce con rapidez buenas estimaciones dentro de un margen de error tolerable.
El sistema permite una búsqueda y selección rápida de eventos, que pueden ser complementadas con un análisis detallado de los datos brutos disponibles.
Se utilizan tanto datos casi en tiempo real (Near Real Time - NRT) como datos de reanálisis (Science Ready).
Terminología¶
Notas sobre la nomenclatura.
Alertas¶
El uso de la palabra «alerta» como sinónimo de evento:
Amenaza: representa una medida del riesgo inminente de deforestación y degradación forestal dentro de una ARP. El IMAZON usa una distancia de 10 km para indicar la zona del entorno de una ARP en que la ocurrencia de deforestación y degradación forestal indican una amenaza.
Presión: ocurre cuando la deforestación se manifiesta dentro de la ARP y conduce a pérdidas de servicios sociales y ambientales, e incluso a la reducción o restablecimiento de los límites de la ARP. Es decir, es un proceso de degradación ambiental interno que puede conducir a la desestabilización legal y ambiental de la ARP.
Alerta: representa una advertencia o señal de que ha ocurrido un evento de deforestación y degradación forestal.
Focos de calor: detección de lugares con vegetación en llamas a través de imágenes digitales de sensores satelitales. Los siguientes términos tienen el mismo significado: foco / punto de quema, foco / punto de fuego, foco / punto de incendio, punto activo y brote.
Área con deforestación de tala rasa: ocurrencia de supresión total de vegetación nativa.
Área con degradación forestal: ocurrencia de remoción parcial de vegetación nativa como resultado de actividades de explotación de madera, minería o quemas.
Cantidad de áreas deforestadas: valor cuantitativo de las alertas de deforestación.
Cantidad de áreas degradadas: valor cuantitativo de las alertas de degradación forestal.
Áreas protegidas¶
Las áreas protegidas son lugares delimitados y gestionados que están destinados a la preservación y uso sostenible de un conjunto representativo de ecosistemas de singular valor científico, cultural, educativo, estético, paisajístico o recreativo. Los tipos de áreas protegidas son Unidades de Conservación, Tierras Indígenas, Quilombos y áreas reglamentadas de uso comunitario.
Colección de datos¶
Constituye un conjunto de datos atribuido a la misma fuente, metodología, etc. Puede referirse a alertas / eventos, pero también a territorios.
Ejemplos:
ISA;
DETER INPE (incluye la Amazonía Legal brasileña y el bioma Cerrado);
PRODES INPE;
Tablero de la Amazonía SERVIR;
FIRMS VIIRS;
FIRMS MODIS;
SAD IMAZON.
Conjunto de datos (Dataset)¶
Es un conjunto de datos distribuido en un solo paquete / archivo. Una misma colección puede estar compuesta por varios paquetes. A depender de la colección, algunos paquetes pueden ser incrementales mientras otros representan un período completo o períodos específicos del conjunto.
Las colecciones de datos también pueden tener distintos paquetes con recortes específicos.
Ejemplos:
La colección del Tablero de la Amazonía tiene paquetes para las fechas 20201231 y 20210506 que representan distintos períodos de datos;
El DETER tiene paquetes para la Amazonía Legal y el bioma Cerrado, y el archivo
deter-amz-public-2021mar29.zipreferente a una fecha (en este caso el 2021-03-29) y a un conjunto de datos (amz).
Shapefile¶
Un shapefile es un formato de datos vectoriales que se utiliza para almacenar la posición, forma y atributos de las entidades geográficas. Se almacena como un conjunto de archivos relacionados y agrupa una clase de entidades. Los shapefiles, por lo general, contienen entidades grandes con muchos datos asociados. Representa un archivo dentro de un conjunto de datos (dataset), es decir, es un conjunto de datos geoespaciales de un paquete más grande de datos.
Por ejemplo, la colección DETER tiene conjuntos de datos para la Amazonía Legal y el bioma Cerrado (distribuidos en paquetes separados).
De esta forma, una misma colección puede ser alimentada por varios importadores, cada uno de ellos dedicado a trabajar con múltiples conjuntos de datos (dataset) – y cada conjunto de datos (dataset) con varios shapefiles. Las colecciones también se pueden obtener directamente de otras bases de datos.
Importador (importer)¶
Es un procedimiento de importación para una colección. Por ejemplo, FIRMS VIIRS y FIRMS VIIRS Archive son dos importadores diferentes para la misma colección, también llamada «FIRMS VIIRS».
Fase (phase)¶
Etapa relativa a la carga de datos del sistema. Por ejemplo:
Etapa 0: conjuntos de datos que son requisitos para todos o la mayoría de los importadores de eventos. Los datos como mapas de biomasa y cobertura vegetal componen la etapa 0, así como las tablas de territorios;
Etapa 1: conjuntos de eventos de importación periódica.
Etapa (stage)¶
Etapa relativa a la carga de la base de datos. Por ejemplo, una importación se puede dividir en las siguientes etapas:
Extraer (Extract): los datos se extraen de una o más fuentes de origen;
Cargar (Load): los datos se cargan en una base de datos;
Convertir (Transform): los datos se convierten para ajustarse a un modelo de datos.
Línea de importación (pipeline)¶
Secuencia de etapas en la incrustación de datos por parte de un importador.
Por ejemplo, la ELT se compone de la secuencia de etapas Extraer, Cargar y Convertir (Extract, Load, Transform).
Operación (operation)¶
En el contexto de los importadores, cada etapa se puede dividir en varias operaciones, que realizan tareas específicas en los conjuntos de datos.
Exportador (exporter)¶
Un exportador es la contraparte de su respectivo importador. Lleva a cabo la exportación de datos usados o procesados por el sistema para que puedan ser utilizados por otros sistemas o incluso por otras personas y entidades que quieran mantener instancias propias de Alertas+.
Mientras en una API u otro sistema dinámico se consultan los datos dinámicamente, el papel de los exportadores es realizar una exportación bruta, específica o periódica de los datos.
Subsistema (subsystem)¶
Porción modular de Alertas+ responsable por rutinas especializadas.