Especificação¶
Especificação do sistema Alertas+ - Alertas+ de Pressões e Ameaças em territórios.
Versão 1.0.0 - Ciclo v2.0.0 - 2021.
Por Antonio Oviedo, Alana Almeida de Souza, Cicero Augusto, João Ricardo R. Alves, Silvio Carlos, Tiago Moreira dos Santos, William Pereira Lima, Juan Doblas.
Contato: alertas@socioambiental.org.
Resumo¶
Estudos recentes têm demonstrado o alto grau de efetividade das áreas protegidas para manter a cobertura de floresta, reforçando seu papel como escudos do desmatamento e apontando a necessidade de fortalecimento de políticas públicas para proteção desses territórios. Doblas e Oviedo (2021) analisaram as trajetórias de mudança de uso da terra durante 33 anos (entre 1985 e 2018) em um conjunto de 1648 áreas protegidas de ocupação tradicional e zonas de amortecimento correspondentes, em todos os biomas brasileiros. Os resultados indicam uma progressão no desmatamento com o tempo, sendo essa tendência maior no entorno das áreas protegidas de ocupação tradicional que em seu interior. As Terras Indígenas da Amazônia, por exemplo, são as áreas protegidas que mais preservam a cobertura vegetal, ou seja, apenas 1,2% do território perdeu sua cobertura vegetal.
Somando-se a estes estudos, esta especificação trata da incorporação, modelagem, análise e disponibilização de dados para apoiar a produção de conhecimento ambiental sobre as áreas protegidas (ARPs), assim como o desenvolvimento de um painel de visualização sobre alertas de desmatamento e degradação florestal na Amazônia Legal que compõem o sistema Alertas+.
Ela ainda documenta decisões de design, engenharia e pressupostos metodológicos usados nas estimativas ágeis de alertas de pressões/ameaças territoriais.
A modelagem proposta no sistema Alertas+ permite a continuidade de pesquisas sobre as trajetórias de mudança de uso da terra e a efetividade das áreas protegidas. A compreensão dos fatores responsáveis pelas trajetórias de mudança de uso da terra é fundamental para o planejamento e formulação de políticas públicas de ordenamento territorial.
Objetivos¶
O Alertas+ busca solucionar diversos problemas, especialmente nas seguintes dimensões:
Informativa: responder rapidamente diversas perguntas sobre ameaças ocorrendo dentro e fora de áreas protegidas.
Narrativa: necessidade comunicar explicitamente o papel das áreas protegidas como “guardiãs da floresta” e prestadoras de serviços socioambientais. Nos casos em que áreas protegidas estão ameaçadas, o Alertas+ apoia na identificação das pressões nestes territórios.
Fortalezas¶
O Alertas+ possui as seguintes características:
Resiliência: não depende apenas de uma única fonte de dados, estando preparando para eventuais problemas de acesso, atualização e qualidade de fontes específicas.
Exportação de dados para formatos abertos.
Dados disponíveis via API podem ser utilizados em outros sistemas.
Projeto estruturador para importação, processamento e disponibilização de dados geoespaciais: novos conjuntos de dados podem ser facilmente incorporados ao sistema.
Importações periódicas e automáticas com supervisão humana garantem análises de qualidade e próximas do tempo real.
Diferenciais¶
O Alertas+ pretende ser um sistema complementar a outros já existentes, contribuindo com os seguintes diferenciais:
Preenche a lacuna de dados cruzados com áreas protegidas usando o banco de áreas plotadas pelo ISA, amplamente reconhecido pela sua qualidade.
Oferece uma única interface onde dados de inúmeras fontes são disponibilizadas para análise e comparação.
Permite muitas possibilidades de cruzamentos e perguntas a um grande banco de dados dinâmico. O painel de dados do Alertas+ permite a visualização dos conjuntos importados assim como a seleção avançada dos recortes territoriais e espaciais.
Facilidade de uso e entendimento, tanto para público geral como também para especialistas: o painel possui dois modos, básico e detalhado, com delimitação dos modos com números maiores e menores de perguntas possíveis que ajudam numa curva de aprendizado suave.
Multilíngue (portugês, inglês e espanhol).
Funcional em dispositivos móveis.
Realização de estimativas experimentas de emissão de carbono.
É baseado no modelo de ciência aberta, onde software livre e dados abertos permitem a reprodutibilidade dos cálculos assim como o aprimoramento do sistema de maneira comunitária e o aumento da resiliência com um maior número de instâncias do sistema em utilização.
Visão geral¶
O desenvolvimento do Alertas+ abrangiu os seguintes subsistemas para coleta e processamento de conjuntos de dados:
O desenvolvimento de um subsistema que realize a descarga e incorporação de conjuntos de dados mediante o cruzamento com uma base geoespacializada de áreas protegidas.
O desenvolvimento de um subsistema para análise dos dados incorporados, discriminando as classes mapeadas por faixas períodos de período temporal arbitrárias (incluindo, mas não somente: diário, quinzenal, mensal, anual e total) e com os recortes espaciais como Terras Indígenas (TIs), Unidades de Conservação (UCs) e respectivos buffers, estados, municípios e bacias hidrográficas; assim como a preparação dos resultados em diversas saídas (API, CSV, JSON, GeoJSON e shapefile).
A implementação de rotinas periódicas de alimentação, atualização de base de dados geográficos, cruzamentos e as várias saídas de dados usando o subsistema de descarga e incorporação descrito anteriormente.
A implementação de uma API Web utilizando o subsistema de análise já mencionado.
A análise de requisitos e modelagem de dados proposta pela equipe do ISA também previu:
O fornecimento de documentação para as bibliotecas, subsistemas e bancos de dados desenvolvidos.
Que todo código fonte produzido precisa estar legível, bem estruturado e bem documentado.
Que o código fonte e a documentação sejam lançados como software livre de acordo com a licença GNU GPL versão 3 ou superior.
Que os dados necessários para que terceiros rodem a aplicação também sejam disponibilizados.
Ciclos de desenvolvimento¶
O desenvolvimento inicial do sistema Alertas+ foi dividido em dois ciclos:
Ciclo 1: prova de conceito e estruturação básica (2020):
Desenvolvimento de rotina para coleta e atualização automática dos dados de desmatamento do DETER.
Protótipo de frontend de visualização de dados (Alertas+).
Ciclo 2: incorporação de novos dados, aprimoramento e lançamento público (2021):
Ampliação do conjunto de dados: PRODES (INPE) (incluindo os dados de desmatamento acumulado até 2007), FIRMS MODIS (NASA), FIRMS VIIRS (NASA), Amazon Dashboard (SERVIR) e SAD (IMAZON).
Transformação do protótipo Alertas+ num produto acessível ao público.
Código fonte¶
O projeto resultou nos seguintes repositórios de código:
Backend: responsável pela incorporação, análise e disponibilização de cômputos.
Frontend: interface web de consulta.
Todo código fonte está disponível sob a licença GNU GPL v3.
Dados abertos¶
O Alertas+ é um sistema inteiramente baseado em dados abertos:
Utiliza conjuntos de dados de terceiros que estão publicamente disponíveis.
Para os dados compilados pelo ISA, uma página de downloads mantém conjuntos gerados automática e periodicamente e que também podem ser incoporados automaticamente por instâncias do backend.
Dados de terceiros são cobertos por suas respectivas licenças, enquanto que os dados produzidos pelo ISA são disponibilizados pela licença Creative Commons CC-BY-SA.
Detalhamento da solução¶
E1 - Modelo de Dados¶
E1.1 - Entidades e Relações¶
As bases de dados modeladas atendem o modelo de Entidade-Relação deste projeto baseado nas entidades básicas descritas abaixo. Porém, tanto as entidades e relações finais assim como o modelo da base de dados podem ser repactuadas durante os próximos ciclos de desenvolvimento, cabendo revisão e readequação conforme necessário:
Evento de pressão/ameaça: também chamado de “alerta”, é a entidade básica dos cômputos, presente no espaço e no tempo. A base de dados deve ser genérica a ponto de suportar diversos tipos de evento como DETER, focos de incêndio FIRMS etc. Um evento pode ser ponto ou área georreferenciada.
Terrirótio: também doravante chamado de recorte, é a entidade geoespacializada onde ocorrem eventos, como por exemplo Terra Indígena (TI), Unidade de Conservação (UC) e buffers/entornos associados a cada uma destas áreas; estados, municípios e bacias hidrográgicas da Amazônia legal.
As relações entre as entidades são dadas através do seguinte diagrama:
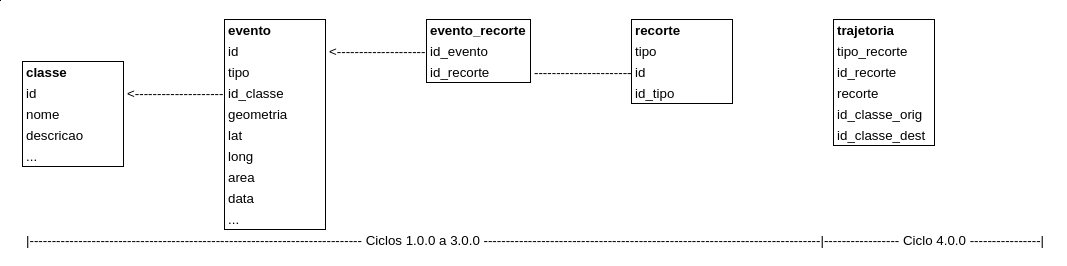
onde:
evento pode ser um evento DETER, Foco de Calor, etc., contendo campo geoespacial – polígono ou ponto –, área (quando cabível) e referência para classe do evento (equivale à classe do DETER) e município de ocorrência.
classe representa um elemento de uma biblioteca de classes.
recorte é a entidade geoespacial (TI, UC, QUI, CAR, Município, UF, etc.) onde ocorrem os eventos e que pode ser relacionada a outras bases de dados e tabelas dedicadas a essas entidades através dos campos recorte.tipo e recorte.id_tipo.
A abstração feita no modelo de dados para as entidades evento e territórios permite que uma série de conjuntos de dados seja tratada uniformemente, o que consolida rotinas de cruzamento e análise e também facilita a importação de novos conjuntos, o que é exemplificado pelo diagrama a seguir:
PRODES --.
\
SAD ----.
\
DETER ---------> Eventos
´
Amazon Dashboard -----´
´
FIRMS ---´
Geo ISA (ARPs) --.
\
IBGE ------> Territórios
´
INCRA --´
E1.2 - Modelo da Base de Dados¶
Enquanto que o modelo de entidades e relações oferece uma visão de nível mais alto para a forma dos conjuntos de dados, o modelo da base de dados indica como na prática as entidades estarão armazenadas tendo em vista a otimização das consultas.
E1.3.1 Pressupostos da modelagem¶
Os seguintes pressupostos foram assumidos para a criação do modelo da base de dados:
No futuro próximo, possivelmente haverá um aumento considerável dos eventos de pressão e ameaça, o que implica em grandes conjuntos de dados a serem incorporados.
A criação de novos cômputos e cruzamentos deve ser simples a ponto de não necessitar de remodelagem do banco de dados.
O sistema deve ter performance suficiente para realizar seleções arbitrárias sem um tempo de espera muito grande.
E1.3.2 - Bases canônicas e derivadas¶
Para satisfazer tais requisitos, foram consideradas dados em três modalidades:
Dado bruto: é aquele tal como obtido junto à fonte, por exemplo arquivo zip, shapefile etc, cujo armazenamento ocorre conforme disponibilidade de espaço e para fins de conferência, salvaguarda e usos futuros.
Base de dados canônica: onde eventos e recortes seguem suas estruturas originais e são atualizadas apenas pela instituição de origem (autoria/autoridade), servindo como dado de referência tanto para os fins desta especificação quanto para salvaguarda de dados e para aplicações futuras. Exemplos de bases canônicas já existentes nos bancos corporativos do ISA incluem Focos de Calor (INPE) e Violência (SisArp / CIMI); tais bases disponíveis podem ser usadas em ciclos futuros do Painel.
Base de dados derivada: cômputos são calculados a partir desses dados canônicos e são armazenados em estruturas derivadas que são estruturas renormalizadas para otimizar consultas; os dados derivados em certa medida são dados redundantes em relação aos dados canônicos, isto é, podem ser cópias dos dados canônicos em estruturas mais apropriadas para consumo final ou mesmo o resultado de computações feitas a partir dos dados canônicos.
E1.3.3 - Segmentação e particionamento¶
Para otimizar consultas, foi considerado que tabelas derivadas de eventos sejam segmentadas e/ou particionadas por:
Tipo de evento.
Recorte.
Faixa de período ou data.
A depender da conveniência e necessidade, tabelas derivadas também podem ser renormalizadas.
Recomendação: avaliar, ao longo da implementação se a segmentação, o particionamento e a desnormalização precisam ser realizados para todos os eventos, podendo ser feita de acordo com a necessidade em tipos de eventos com muitas ocorrência. No entanto, a adoção de uma escolha uniforme e escalável pode reduzir a quantidade de código, já que desta forma as exceções à regra são evitadas.
Recomendação: realizar o particionamento por data e a segmentação por tipo de evento e recorte. O particionamento por data será implementado usando a respectiva funcionalidade do PostgreSQL, enquanto que a segmentação é implementada com a simples criação de tabelas de eventos por tipo de evento e recorte.
E1.4 - Etapas de Incorporação¶
Para as etapas de incorporação, foram consideradas as seguintes alternativas:
E1.4.1 - (Alternativa 1) Calcular e Compilar¶
Descarga do dado bruto: quando o conjunto de dados é obtido junto à fonte e em seu estado bruto.
Importação: **dados canônicos **são importados no formato tal qual estão disponibilizados pela origem, realizando correções e validações de dados apenas para correção de erros, checagens e conversão de formatos.
Cálculo de Cômputos: realização de cruzamentos de dados canônicos de eventos e recortes e armazenamento do resultado em estruturas derivadas sem segmentação/particionamento/renormalização.
Compilação: quando os cômputos são segmentados/particionados/renormalizados para otimizar consultas dinâmicas.
E1.4.2 - (Alternativa 2) Compilar e Calcular¶
Descarga do dado bruto: quando o conjunto de dados é obtido junto à fonte e em seu estado bruto.
Importação: **dados canônicos **são importados no formato tal qual estão disponibilizados pela origem, realizando correções e validações de dados apenas para correção de erros, checagens e conversão de formatos.
Compilação: cômputos são segmentados/particionados/renormalizados para otimizar cálculos e consultas dinâmicas.
Cálculo de Cômputos: realização de cruzamentos de dados compilados de eventos e recortes e armazenamento do resultado em estruturas derivadas.
E1.4.3 - (Alternativa 3) Segmentar e Calcular¶
Descarga do dado bruto: quando o conjunto de dados é obtido junto à fonte e em seu estado bruto.
Importação: dados canônicos são importados no formato tal qual estão disponibilizados pela origem, realizando correções e validações de dados apenas para correção de erros, checagens e conversão de formatos.
Cálculo de Cômputos: realização de **cruzamentos **de eventos e recortes e armazenamento do resultado em estruturas derivadas modeladas com segmentação por tipo de evento e recorte, além de particionamento por data.
E1.4.4 - (Alternativa 4) Particionar, Segmentar, Calcular¶
Descarga do dado bruto: quando o conjunto de dados é obtido junto à fonte e em seu estado bruto.
Importação: **dados brutos são canonizados, **isto é, são importados no formato tal qual estão disponibilizados pela origem (dado bruto) e opcionalmente particionados por data, realizando correções e validações de dados apenas para validação, correção de erros, checagens e conversão de formatos, por exemplo na correção de datas que estejam incorretas.
Cálculo de Cômputos: realização de **cruzamentos **de eventos e recortes e armazenamento do resultado em estruturas derivadas modeladas com segmentação por tipo de evento e recorte, além de opcionalmente particionamento por data, tarefa realizada pela Biblioteca de descarga e incorporação.
Compilação: opcionalmente e caso necessário, cômputos podem ser segmentados/particionados/renormalizados para otimizar consultas dinâmicas, tarefa realizada pela Biblioteca de análise (API).
A seguir, uma breve discussão de prós e contras de cada otimização.
Compilação: A primeira alternativa facilita a codificação dos cômputos, porém pode ocasionar retrabalho na etapa de compilação, isto é, requer mais consultas ao banco e código adicional. Por outro lado, a compilação antes da codificação de cômputos (segunda alternativa) pode tornar o cruzamento de dados bem complexo, já que o objetivo da compilação é reduzir o acesso ao banco de dados pela produção de conteúdo na estrutura usada pela aplicação frontend (cache do Painel). Em geral, recomenda-se que os dados armazenados no cache do frontend sejam compilados apenas quando necessário, dando preferência para cache de dados sem compilação.
Particionamento: Enquanto o particionamento por data pode ter um incremento de performance no acesso aos dados durante os cálculos e outras consultas, ela pode complicar os cálculos por conta de limitação do uso de chaves externas nas tabelas, no caso do PostgreSQL, o que pode ser um fator limitante no caso de cruzamento de informações relacionais entre tabelas mas que não deve ter um problema no caso de cruzamentos geoespaciais.
Segmentação: Como a quantidade de recortes tende a ser muito menor do que a quantidade de eventos, optou-se por recomedar sua segmentação, o que pode reduzir o tamanho de tabelas e manter por padrão eventos separados por recorte, porém faz com que os eventuais relacionamentos entre dois recortes de tipo distinto requeiram consultas com JOIN. Outras possibilidades podem levar em conta o sub-particionamento ao invés da segmentação, porém podem adicionar muitos níveis de complexidade na manutenção das bases de dados.
Abordagem escolhida¶
Durante a implementação todas essas alternativas foram avaliadas, tendo sido optado pela seguinte abordagem tendo em vista uma solução genérica, escalável e evitando criar exceções no tratamento de dados:
Fluxo de incorporação do tipo ELT (Extract, Load, Transform), onde o dado canônico é baixado, em seguida carregado no banco de dados e aí sim transformado para o modelo de dados adotado.
Na etapa de transformação ocorre tanto o cálculo de cômputos como compilações para otimizar consultas.
Optou-se pelo particionamento por tipo de evento.
Uso de diversas otimizações de base de dados, como indexação e evitar fragmentação dos dados inseridos, ordenando eventos por data ao incluí-los nas tabelas.
E1.5 - Periodicidade¶
Durante as avaliações preliminares, foram consideradas as seguintes possibilidades para seleção de intervalos de tempo:
Seleção arbitrária.
Divisão mandatória em intervalos fixos (mensal, anual etc).
Possibilidades de abrangência do conjunto de dados:
Integral: os conjuntos de dados são inteiramente desde a data mais antiga até a mais recente.
Parcial: dados muito antigos não são utilizados por conta da disponibilidade de recursos computacionais.
Considerações sobre velocidade de consultas (queries) ao banco de dados e espaço de armazenamento foram avaliadas e assim foi escolhida a opção da seleção arbitrária de datas.
E2 - Subsistema de descarga e incorporação (“importer”)¶
O subsistema importer do Alertas+ é responsável pelas rotinas de importação e
cruzamento de dados.
E2.1 - Requisitos¶
Tal subsistema de coleta dos conjuntos de dados é dividida em diferentes
importers (importadores), cada um deles responsável por:
Baixar os conjuntos de dados brutos a partir do endpoint de disponibilização do conjunto de dados.
Incorporar os conjuntos de dados baixados em bases de dados tabular e geoespacial (dados canônicos e derivados).
Ser capaz de rodar periodicamente e automaticamente, funcionando tanto para a alimentação de bases de dados vazias (sem dados) quando na atualização de bases de dados existentes.
Ser capaz de rodar em sistema operacional GNU/Linux sem interface gráfica, por exemplo num cronjob.
Ser compatível com o modelo de dados especificado neste documento.
Portanto, cabe a cada importador não apenas o download dos dados brutos como a incorporação nas bases de dados canônicas e derivadas de acordo com a modelagem escolhida. Para isso, é necessário que ela realize os cruzamentos dos eventos com os recortes durante o processo de ingestão dos dados nas bases.
E2.2 - Fluxo de incorporação¶
O fluxo de incorporação dos dados deve ser uma rotina estática (gera dados que ficam armazenados), automática (roda sem intervenção manual) e periódica (roda com uma frequência a definir), devendo estar de acordo com o seguinte diagrama:
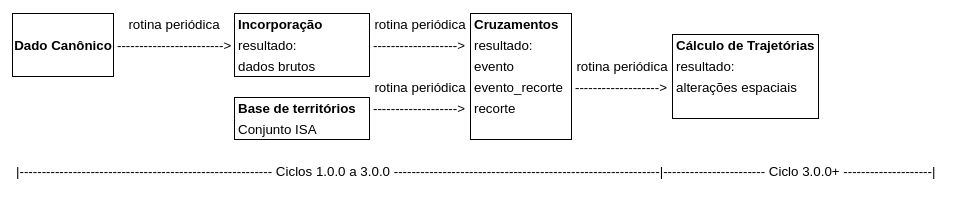
Os cruzamentos são produzidos no encontro dos dados de evento com os dados de bases já existentes sobre os recortes geoespaciais e de acordo com a modelagem de dados tratada no item E1.2.
O subsistema de importação conta com scripts e bibliotecas genéricas que reduzem bastante a quantidade de código necessária para cada importador, cuidando também da criação de metadados de importação consumidos pelo painel de consultas.
Os resultados são calculados para cada área protegida e para cada tipo de evento (desmatamento, queimada), permitindo a visualização das áreas protegidas de forma individualizada.
A maior parte dos importadores adota o pipeline Extract, Load and Transform (ELT), porém outras linhas são suportadas, como Extract, Transform, Load (ETL) ou até mesmo mais simples como LT (Load, Transform).
Rotinas da fase de transformação são divididas em “operações” que realizam tarefas específicas de cruzamento e análise.
E2.3 - Discriminação de classe DETER¶
No caso espécifico do DETER, a discriminação das classes mapeadas por faixas de períodos arbitrários será alterada em relação à canônica fornecida pelo INPE.
O esquema de classes canônico é descrito pela tabela a seguir:
| Classe nível 1 | Classe nível 2 |
|---|---|
| Desmatamento | desmatamento com solo exposto |
| desmatamento com vegetação | |
| mineração | |
| ----------------------- | -------------------------------------- |
| Degradação | degradação |
| cicatriz de incêndio | |
| ----------------------- | -------------------------------------- |
| Exploração madeireira | corte seletivo tipo 1 (desordenado) |
| corte seletivo tipo 2 (geométrico) |
No entanto, o Alertas+ utiliza a seguinte classificação:
| Classe nível 1 | Classe nível 2 |
|---|---|
| Desmatamento | desmatamento com solo exposto |
| desmatamento com vegetação | |
| ---------------- | --------------------------------------------- |
| Mineração | área minerada |
| ---------------- | --------------------------------------------- |
| Queimada | cicatriz de incêndio |
| ---------------- | --------------------------------------------- |
| Degradação | degradação |
| corte seletivo tipo 1 (desordenado) | |
| corte seletivo tipo 2 (geométrico) |
Motivação:
Essa categorização ajuda a comparar de forma mais explícita os eventos de focos de calor com o dado DETER, discriminando a importância aos efeitos dos incêndios.
Permite isolar cicatrizes de fogo para fazer correlação com outras fontes de focos de calor.
Eventos na categoria “degradação” em geral precedem o desmatamento, podendo ou não resultar no desmatamento de corte raso.
O fogo pode fazer parte do processo de desmatamento ou não.
Individualizar a categria “mineração” permite análises específicas sobre esse tipo de pressão/ameaça às áreas protegidas.
Exemplos:
No PIX (Parque Indígena do Xingu) ocorrem cicatrizes de incêndio, mas pouco desmatamento ou degradação florestal.
A degradação pode estar associada ao início do desmatamento de corte raso.
Invasores ocupam uma área e realizam a queimada da vegetação abaixo do dossel florestal (broca).
Após a queima e/ou retirada de árvores do sub-bosque, as atividades de desmatamento podem envolver a retirada de árvores maiores por meio de motossera ou o uso de maquinário agrícola caso o terreno não apresente árvores grandes de interesse econômico.
No sul da Amazônia, na transição para o cerrado, existe a ocorrência de fogo sem relação com os processos de desmatamento, mas sim com prática de manejo da paisagem ou sistemas agrícolas (i.e. queimadas que escaparam de fazendas e podem se tornar incêndios florestais de grandes extensões).
Convém observar, também, que no eventual caso da incorporação de dados do DETER Cerrado, este é um dado sem divisão de classes, isto é, todos os eventos se referem a alertas de desmatamento de corte raso e assim classificados como tal na rotina de importação. Fazendo isso, os dois conjuntos de dados ficam compatíveis (Amazônia Legal e Cerrado), permitindo uma seleção única na interface já que ambos compartilham o mesmo tipo de evento.
Para informações atuais sobre a definição de classes do DETER, consulte o config.py do respectivo importador.
E2.4 - Discriminação de classes de outros tipos de evento¶
Para outros tipos de evento, seguiu-se preferenciamente a definição canônica de classes ou, na ausência da mesma, foi realizada uma classificação de acordo com a cobertura vegetal existente no local e data do evento.
As informações mais atuais sobre definição de classes estão nos arquivos
config.py de cada importador. A lista a seguir serve apenas de exemplo para
as classes de nível 1.
Para eventos de fogo Amazon Dashboad:
Nível 1: refere-se ao tipo de fogo:
1: Savana e pasto (savanna and grassland).
2: Agricultura (small clearing and agriculture).
3: Sub-bosque (understory).
4: Desmatamento (deforestation fires).
Para focos de incêndios ativos FIRMS:
Classes determinadas de acordo com a cobertura vegetal no local da ocorrência, usando para isso a coleção 5 do MapBiomas (https://mapbiomas.org/colecao-5) e considerando a cobertura vegetal respectivamente à data do evento.
Para o desmatamento Prodes:
Nível 1: classe única (desmatamento).
Para alertas de desmatamento e degradação SAD:
Nível 1:
1: Desmatamento
2: Degradação
E3 - Subsistemas de análise (“query” e “API”)¶
O papel do subsistemas de análises é produzir cômputos analíticos sobre os dados coletados, sendo uma rotina dinâmica (calcula e retorna dados sem armazená-los em bancos), automática (não necessita de intervenção manual para se realizar) e aperiódica (roda somente de acordo com solicitações ao dado).
E3.1 - Fluxo de análises¶
A computação das análises é representada de acordo com o diagrama de interação sequencial abaixo:

A produção das análises serão obtidas através de chamadas feitas a partir de um frontend tendo como destino uma API que realizará as consultas dinâmicas (queries) nas bases de dados discutidas na seção E1.2.
Todas as análises a seguir são consideradas de acordo com o modelo proposto na seção anterior “modelagem de dados”, de modo que no futuro seja possível reaproveitar com facilidade as rotinas desenvolvidas para novos conjuntos de dados (eventos e classes).
E4 - Shapefile de áreas protegidas mantidos pelo ISA¶
As áreas protegidas (Terras Indígenas e Unidades de Conservação) na Amazônia Legal foram digitalizadas em ambiente SIG (sistema de informações geográficas) baseadas nos memoriais descritivos dos documentos oficiais de criação ou alteração do perímetro. As áreas são plotadas na escala 1:100.000. Para as Unidades de Conservação estaduais, adotamos as bases do ICMBio/MMA como referência dos dados espaciais, complementadas com as informações dos órgãos estaduais do SISNAMA. Quando não há memorial descritivo da área protegida ou se ele possui erros que impedem a plotagem do perímetro, dados vetoriais e matriciais obtidos em órgãos oficiais federais e estaduais (i.e. FUNAI, MMA e secretarias estaduais) são utilizados para revisão e/ou complementação, bem como documentos não cartográficos como, por exemplo, planos de manejo das Unidades de Conservação.
Os dados espaciais de municípios e estados utilizados como referência para a plotagem das áreas protegidas têm origem tanto do SIVAM (Sistema de Vigilância da Amazônia, 2004), na escala 250 mil, quanto da base cartográfica contínua para o Brasil na escala 250 mil (IBGE, 2015). Além destas bases oficiais, rasters globais (i.e. Google) e imagens de satélite da série Landsat também auxiliam no processo de construção dos limites caso existam limitações nos dados vetoriais.
Todas as feições foram transformadas para o sistema de coordenadas geográficas e referenciadas ao Datum Sirgas 2000.
E5 - Buffers e Máscaras¶
Atualmente e para uma ARP individual, a contagem de eventos é calculada dentro da unidade espacial e em três buffers simples:
De 0 a 3km: vindo da regulamentação de UCs; no caso das TIs seria para compatbilização.
De 3 a 10km: valor arbitrário.
De 0 a 10km (soma dos buffers 1 e 2): também valor arbitrário.
Os dados espaciais referentes aos buffers das áreas protegidas foram delimitados em ambiente SIG a partir da função buffer.
Para ciclos de desenvolvimento posteriores, podem ser consideradas outras possibilidades de buffers que podem ser criados com critérios mais complexos, incluindo aqueles “para dentro das ARPs”.
No caso de conjuntos de dados com abrangência além da Amazônia Legal Brasileira, uma máscara é aplicada para limitar o conjunto derivado de eventos apenas para a Amazônia Legal.
E6 - Saídas analíticas¶
Os períodos de análise são arbitrários e caracterizados por datas inicial e final, podendo também representar períodos definidos como diário, quinzenal, mensal, anual e total.
As saídas do painel que integra os dados envolvem os seguintes resultados:
Área total (e por classes de nível 1) de alertas DETER (anual, mensal e acumulado) nos seguintes recortes espaciais: Terras Indígenas, Unidades de Conservação, buffer ARP de 3km e buffer ARP de 10km); municípios (MUN), Unidades da Federação e bacias hidrográficas.
Os resultados trazem os históricos de ocorrência em cada unidade territorial, inclusive nos buffers, dentro do limite da Amazônia Legal Brasileira, podendo ser acumulados historicamente, anualmente, mensalmente ou qualquer outro cômputo necessário.
As Áreas de Proteção Ambiental (APAs) podem ser selecionadas separadamente, ou seja, distintamente do conjunto de UCs.
Ocorrência de sobreposição entre desmatamento em períodos distintos. Para estes casos, é preciso fazer uma contabilização e eventualmente confirmar com as equipes técnicas responsáveis por cada conjunto de dados para entender a metodologia e o motivo de ocorrência destes casos, talvez como controle de qualidade do dado.
Já para o ciclos de desenvolvimento futuros, as seguintes análises podem ser consideradas e são compatíveis com o modelo de dados adotado:
Mudanças de geometria/classe ao longo do tempo, respondendo à seguinte questão: Quais são as trajetórias das classes dos eventos (nível 1 e 2)? O painel poderia apresentar o que ocorreu em determinado período (livre escolha) por unidade geográfica (TI ou UC). Um exemplo disso é a plataforma Mapbiomas, que apresenta a evolução entre dois períodos distintos da mudança de classes. Nesse painel de alertas, seriam representadas as mudanças que ocorrem entre as classes 1 e 2.
Modificações ao longo do tempo na área de cada classe em decorrência da dinâmica do processo de desmatamento, respondendo à seguinte questão: Quanto dos eventos - classe degradação e/ou exploração madeireira - se transformaram em eventos (polígonos) da classe desmatamento?
E7 - Painel de consulta¶
O painel de consulta do Alertas+ contém:
Conjuntos de dados disponíveis de desmatamento e degradação florestal.
Tipologia de territórios: áreas protegidas, buffer correspondentes, estados e municípios.
Seletores específicos para a seleção de área protegida, estados, municípios e bacias hidrográficas.
Seletor de recorte temporal: data inicial e data final.
Seletor de escala temporal dos resultados: anual, mensal e quadrimestral.
Seletor de visualização de unidades espaciais no gráfico: 5, 10 ou 20 unidades.
Interface com ferramenta de comparação entre recortes espaciais, datas e fontes de alertas.
E8 - Abrangência¶
Primeira versão pública: Amazônia Legal, com seleção de municípios restrita àqueles presentes nessa abrangência.
Versões posteriores: podem ter maior abrangência, eventualmente incluindo o Cerrado e outras regiões.
Para o caso dos conjuntos do INPE, notou-se que atualmente o TerraBrasilis oferece os conjuntos para a Amazônia Legal e para o bioma Cerrado. Existe sobreposição entre ambos os conjuntos, já que parte da Amazônia Legal está sobreposta a parte do bioma Cerrado.
Há uma hipótese de que o INPE segue neste caso a mesma lógica do Prodes: mapeia fragmentos de florestas no bioma Cerrado e, a partir de uma análise espacial varifica-se a sobreposição entre os polígonos.
Assim, em ciclos posteriores será necessário adaptar a rotina de importação de dados canônicos para excluir essa duplicidade, por exemplo separando o que é referente a Amazônia legal e bioma Cerrado, porém este último não possui variedade de classes mapeadas, ou seja, são só “avisos de desmatamento”, enquanto que no primeiro temos mais classes (desmatamento corte raso, queimadas, mineração, etc.).
E9 - Bacias Hidrográficas¶
Foi utilizada uma base de dados canônica da ANA com revisões realizadas pelo ISA, que resultou numa base de bacias hidrográficas derivada incluindo ajustes das bacias do Rio Negro e Xingu.
O dado canônico apresenta inconsistência por conta de relevo e problemas metodológicos que trazem consequências no nível de resolução para o trabalho que o ISA realiza nessas duas regiões.
Assim, foram realizadas melhorias e até ajustes manuais para corrigir situações nas quais a bacia hidrográfica terminava antes da sua própria foz. Numericamente a bacia hidrográfica resultante não é muito diferente, mas sim em termos de desenho e forma.
Para o Alertas+ é utilizado o nível 2 das bacias hidrográficas desse conjunto.
A forma de incorporação das bacias diferiu dos outros recortes territoriais, valendo uma nota a respeito na seção “Pressupostos, características e limitações”.
E10 - Estimativa de emissão de Carbono¶
O Alertas+ possui uma operação de cálculo de estimativas de emissão de carbono associadas aos eventos.
Esta saída está implementada porém se encontra numa fase experimental de análise, comparação com outras estimativas e calibração de parâmetros de emissão, tendo o seu uso ainda não recomendado.
A interface de consulta do Alertas+ já possui a contabilização do impacto causado pelos eventos analisados pelo usuário, fornecendo o equivalente em carbono emitido, porém esta funcionalidade se encontra atualmente desativada e aguardando homologação final.
Apesar da indisponibilidade deste dado no painel de consultas e a recomendação para que o mesmo ainda não seja utilizado, tal informação já é rotineiramente calculada pelo sistema, estando disponível para consumo via API e também passível de ser calculada independentemente usando o código fonte do Alertas+ e os arquivos de entrada (mapa de biomassa, mapa de cobertura vegetal e os conjuntos de eventos).
Os pressupostos envolvidos nestas estimativas são discutidos adiante na seção “Pressupostos, características e limitações”, enquanto que a presente seção tratará de explicar em linhas gerais os algoritmos de cálculo e em quais referências teóricas e metodológicas eles estão baseados.
O cálculo de emissão está baseado em dois fatores:
Tipo de evento.
Conteúdo de carbono presente no local do evento correspondente ao polígono ou, para eventos pontuais, na cobertura vegetal do ponto correspondente à data de ocorrência do evento.
O sistema possui uma operação de cálculo de carbono emitido para cada evento registrado. Para otimizar o tempo de resposta do sistema, o fator de emissão associado a cada evento é calculado previamente.
O método para estimativa da emissão de Carbono é diferente para eventos poligonais e para eventos pontuais (focos de calor), sendo tratados nas seções a seguir.
Cálculo para o caso poligonal¶
Tipo de evento. Nos eventos poligonais, a emissão associada aos eventos de corte raso será de 100% do carbono associado ao polígono. Já nos polígonos de degradação, a proporção será menor. O índice de emissão das classes de áreas queimadas e degradadas será de 57% e 35%, baseado na pesquisa de Berenguer et al., 2014 (A large-scale field assessment of carbon stocks in human-modified tropical forests).
Essa quantia é calculada mediante uma operação de integração de um dado matricial representando, com uma resolução suficiente, o conteúdo de carbono por hectare (ha) na área de abrangência do sistema. Especificamente, o mapa de carbono utilizado foi desenvolvido pela ESA Biomass Climate Change Initiative.
O valor de densidade de biomassa é extraído no pré-tratamento, a partir de um raster de 100 metros de resolução elaborado pela ESA, e que é a fonte mais confiável de biomassa (segundo vários especialistas):
Para realizar o cálculo, é feita a multiplicação do valor de emissão por ha pela área dos eventos poligonais. Para evitar contagem dupla, esse cómputo sera feito mediante a função
smart_emissions, que irá calcular a área dissolvida dos polígonos que possuem sobreposição e multiplicar pela média da densidade de emissão pré-calculada desses polígonos. Já os polígonos que não tem sobreposição o cálculo será feito por simples adição da emissão individual, calculada multiplicando a área do polígono pela densidade de emissão pré-calculada.
Assim, para polígonos – DETER, SAD, PRODES e Amazon dashboard, por exemplo –, a emissão de carbono é calculada multiplicando o valor de densidade de biomassa no local (centróide do polígono), em MgC/ha pela área do polígono e pelo fator de conversão de biomassa (1 para desmatamento, 0.57 para incêndios e 0.35 para degradação). Esses valores foram extraídos de Berenguer et al (2014).
Cálculo para o caso pontual¶
Tipo de evento. Os eventos pontuais de fogo terão como referência o valor de FRP (potência radiativa de fogo), conforme pesquisa inicial de Wooster, 2002. Esse valor será multiplicado por um fator médio de conversão para emissões de Carbono Equivalente, segundo reportado por Kaiser (2012), que em média é de
39.71 * 1.39 = 55.20para obter toneladas de carbono equivalente emitidas por cada foco detectado.Mas, para obter uma estimativa mais precisa, adotou-se um procedimento mais elaborado, consistindo nas seguintes etapas adicionais:
Cálculo em planilha de fatores de emissão por cobertura de solo.
Preparação de mapas anuais de cobertura de solo a partir da Coleção 5 do Mapbiomas usando o Google Earth Engine.
O computo final de carbono emitido será feito por adição simples da emissão correspondente a cada evento, no caso dos focos de calor,
Para dados pontuais – focos de calor FIRMS, por exemplo – o cálculo de emissão de carbono por incêndios é um importante tema de pesquisa nas ciências ambientais.
No presente desenvolvimento, foram estudadas referências clássicas (sobretudo Kaiser et al, 2012) para determinar a relação entre a potência do fogo (o parámetro FRP, disponível para cada evento) e a emissão de carbono associada.
Outras referências bibliográficas e consultas a pesquisadores do INPE resultaram na definição de um fator médio de 55.20 Mg/W, isto é, a emissão bruta diária de carbono de um foco de calor ativo, em toneladas, equivale a 55.2 vezes o FRP.
Mesmo assim, julgou-se necessário:
Preparar um raster contendo diversas bandas – uma para cada ano desde 1984 – de cobertura vegetal.
Classificar os eventos de focos de fogo de acordo com a cobertura de solo referente ao ano de ocorrência do foco.
Calcular os fatores de emissão de acordo com as coberturas de solo selecionadas a partir do Coleção 5 do Mapbiomas.
Os fatores de emissão são definidos para cada importados no seu arquivo de
configuração config.py, o que permite que os cálculos de emissão sejam
facilmente calibrados.
Tratamento de sobreposições¶
A solução para o tratamento das sobreposições foi a grande dificuldade na implementação:
O problema: na hora de calcular a emissão total associada à uma requisição do usuário, os valores de emissões de cada evento são adicionados para entregar o valor total. O problema surge quando existe sobreposição nos eventos selecionados. Por exemplo, caso o usuário deseje o total de emissões em buffers de TIs, tais buffers podem se sobrepor no caso de TIs contíguas, e com isso os eventos associados estão duplicados total ou parcialmente. Também pode ser o caso de uma seleção de TIs e UCs que têm sobreposições.
A solução precisa: a forma mais precisa de calcular essas emissões seria fazer uma operação do tipo “dissolve” (
ST_Union) desses polígonos, recortar (clipar) o raster de biomassa e calcular a biomassa total associada a esse recorte (clip). Infelizmente esse processamento leva horas, o que o torna inviável para essa proposta de painel. Outra opção seria converter cada polígono em um prisma, com altura equivalente à densidade de biomassa, e no tempo de execução fazer uma operação “dissolve” e um cálculo de volume em três dimensões. Essa opção também se revelou muito lenta e inviável.Como solução adotada, foi realizada a separação dos polígonos que não têm sobreposição dos que têm. A emissão correspondente aos primeiros é feita de forma simples, adicionando as emissões às feições do polígono. Já os polígonos com sobreposição seguem um processo diferente, ou seja, é feito uma operação “dissolve” em área e é calculado o valor médio das emissões por hectare. Depois, esse valor médio é multiplicado pela área total “dissolvida”.
Estimamos que o erro associado a essa simplificação não é muito grande, até porque a proporção de sobreposições é baixa (entre 5 e 10%) no caso de não considerar buffers. Para análises que incorporam buffers o erro pode ser maior, mas acreditamos que o erro associado é muito menor do que o erro associado aos outros parâmetros do cálculo.
Os fatores de emissão relativos a cada tipo de evento serão consignados nos arquivos de configuração correspondentes:
No caso de eventos de tipo poligonal, o fator se refere a MgCe/ha.
Em caso de eventos puntuais, a unidade do fator é MgCe/MJ.
Procedimento para geração do mapa de biomassa¶
Para a geração do mapa de carbono (biomassa), foi utilizado o seguinte procedimento manual:
Download dos arquivos GeoTIFF fornecidos pela ESA Biomass Climate Change Initiative.
Montagem do mapa a partir dos GeoTIFFs baixados usando o QGIS para criar um raster único.
Recorte da área de interesse.
Conversão para uma query SQL importável.
Tal mapa de biomassa se encontra disponível na página de downloads do Alertas+.
Referências¶
E. Berenguer et al. (2014) A large-scale field assessment of carbon stocks in human-modified tropical forests, DOI 10.1111/gcb.12627.
J.W. Kaiser et al. (2012) Biomass burning emissions estimated with a global fire assimilation system based on observed fire radiative power, DOI 10.5194/bg-9-527-2012.
E11 - Formatos e dinâmica de saídas de dados¶
Para as produções dos mapas e outras análises por plataformas web, os resultados obtidos devem estar organizados para serem disponibilizados nos seguintes formatos:
Formato estruturado aberto (CSV, JSON e GeoJSON).
Formato Vetorial (shapefile).
Formato bruto (tabela SQL ou raster).
Interação via web services (API RESTful).
Tiles para consumo dinâmico (Tile Server no formato MVT - Mapbox Vector Tiles).
Os seguintes subsistemas cuidam das saídas de dados:
Parte das saídas é produzida dinamicament (subsistemas de análise “query” e “API”). A API do sistema pode ser consultada programaticamente ou de forma interativa, neste último caso através da página de API do Alertas+.
Uma outra parte, mais estática, é produzida por um subsistema de exportação (“exporter”), estando disponível para download via:
Uso direto do subsistema de importação, através do uso do backend do sistema.
Os arquivos estáticos são automaticamente e periodicamente exportados do sistema, sendo atualmente restritos aos dados que não são de eventos como shapes de territórios e mapas de biomassa e cobertura vegetal.
Os dados de eventos podem ser obtidos diretamente a partir das fontes canônicas.
E12 - Sistema de gestão operacional¶
Para a monitoria e operação do sistema, especialmente para acompanhar os fluxos de incorporação de dados bem como responder a erros, o Alertas+ possui uma instância do Apache Airflow.
Assim como para as rotinas periódicas de manutenção, cada importador possui uma rotina própria no Airflow, conforme a imagem abaixo:
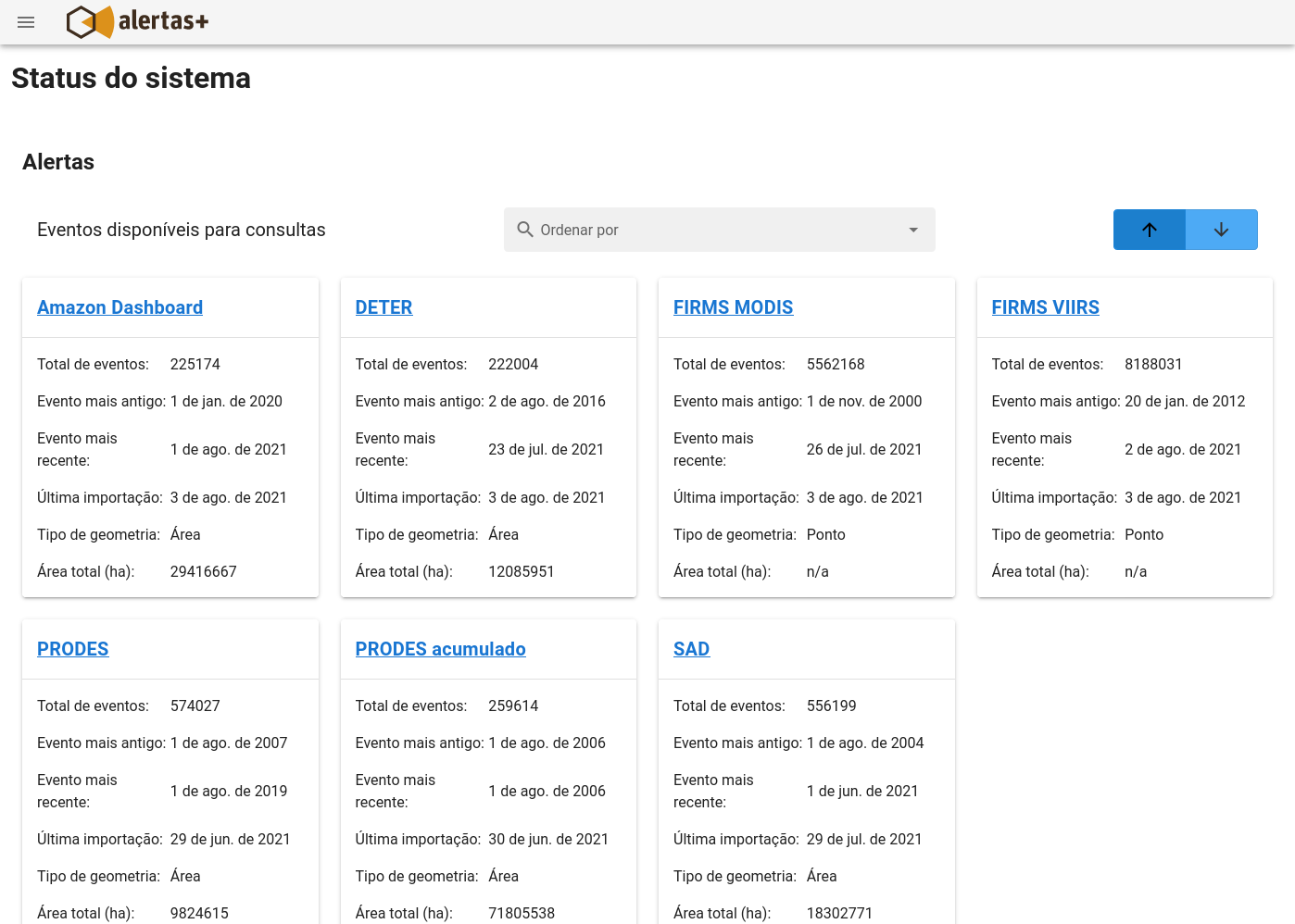
O Alertas+ também conta com uma página de status pública reportando a condição mais recente dos conjuntos de dados:
Pressupostos, características e limitações¶
Na construção do Alertas+, um esforço especial foi empreendido para documentar explicitamente e ao máximo todos os pressupostos e aproximações adotadas não somente dos conjuntos de dados utilizados mas também das escolhas de design e implementação.
Tais pressupostos ajudaram na definição da aplicabilidade do Alertas+ como um sistema expedito de alertas próximo do tempo real.
Quando possível, o processo de homologação ainda trabalhou para avaliar criticamente a validade dos pressupostos.
Instantaneidade de eventos¶
O sistema assume uma instantaneidade nos eventos.
Diferentemente, por exemplo, do Amazon Dashboard, o Alertas+ não regista início e fim de eventos como, por exemplo, início e fim de incêndios, tanto por simplicidade do modelo, quanto para facilitar o uso da interface, pois nem todo conjunto de dados possui a data de término. Essa suposição funciona para análises em longos períodos, porém para intervalos curtos ela é imprecisa e falha especialmente quando o intervalo é mais curto do que a duração do evento.
Eventos são assumidos ocupando uma única data (escala diária), mas o evento de fato pode ter sido mais curto ou mais longo. Este pressuposto está implícito tanto em alguns conjuntos de dados (produto FRP do VIIRS e MODIS) quanto no próprio modelo de dados do Painel (evento numa data com dia/mês/ano); outros sistemas como o Amazon Dashboard consideram data de início e final de incêndio, enquanto este Painel considera apenas uma única data (equivalente ao “start date” do Amazon Dashboard).
Data dos eventos¶
Para alguns conjuntos de dados, a data do evento se refere à data da detecção e não à data da ocorrência, como é o caso do DETER e do PRODES:
No DETER é especialmente relevante compreender a distinção entre o tempo de
ocorrência e o tempo de detecção. Uma floresta pode ser desmatada passo a
passo, mas sua detecção como corte raso ou área degradada ocorre apenas
quando as condições de observação pelo satélite são favoráveis. No DETER,
todo alerta de desmatamento detectado numa imagem, e que não foi detectado
anteriormente, é considerado desmatamento novo independentemente da data
real de ocorrência do evento.
Os dados do DETER podem incluir processos de desmatamento ocorridos em
períodos anteriores ao do mês de mapeamento, cuja detecção não tenha sido
possível, por limitações de cobertura de nuvens ou disponibilidade de
imagens. Por essa razão, é preciso distinguir entre o tempo de ocorrência e
a oportunidade de detecção.
Isto ocorre porque são informações baseadas em imagens dos terrenos afetados que são obtidas periodicamente e não necessariamente no momento em que uma depredação florestal ocorre.
Em outros tipos de eventos como do Amazon Dashboard e FIRMS, a data de ocorrência é mais próxima do realmente ocorrido pois são baseadas na deteção de fogo (focos de calor) na passagem periódica dos satélites com sensores MODIS e VIIRS (este último de alta resolução).
Ausência de processos regenerativos¶
O sistema assume apenas o processo de degradação florestal e não estimamos taxas de regeneração em nenhum nível. Assim, os valores acumulados no Painel (desmatamento, degradação florestal e estimativa de emissão de carbono) podem ser maiores. Para grandes períodos essa diferença pode ser significativa, enquanto que no “near-real time” pode ser negligível.
Temporalidade das Áreas Protegidas¶
Todos os cômputos sobre as Áreas Protegidas consideram-nas em seu perímetro mais recente, isto é, o sistema não leva em consideração eventuais anteriores das ARPs ou mesmo se ela existia ou não na data de registro de um evento.
Mesmo que uma ARP tenha sido criada depois de um evento, o sistema considera que o mesmo ocorreu na área delimitada pela ARP.
Apesar da simplificação que não considera a dimensão histórica da criação e alteração de limites das ARPs, o pressuposto permite uma consistência analítica do histórico de ameaças no recorte territorial.
Simplicidade dos buffers¶
Conforme mencionado na seção E4, atualmente o sistema conta com áreas do entorno (buffers) simples traçadas automaticamente para cada ARP.
Estes buffers simples não levam em conta as sobreposições entre ARPs e entre buffers de ARPs próximas/sobrepostas.
Para evitar dupla contagem de eventos e área afetada, as consultas ao banco de dados do sistema levam tais sobreposições em consideração através de um processo de pré-computação de um algoritmo especial de “smart area” para obter os dados sem dupla contagem de forma ágil.
Outros recortes do tipo área buffer podem ser considerados no futuro, como por exemplo aqueles que considerem somente a porção do território fora das ARPs, isto é, sem sobreposição com outras ARPs.
Estimativas de emissão de Carbono¶
No geral, considera-se que ainda existem uma série de imprecisões em todas as estimativas de emissão de carbono, não somente do Alertas+.
O principal motivo está nas grandes incertezas nas estimativas de estoque de carbono.
Mesmo assim, acredita-se que as estimativas do Alertas+ possam ser utilizadas num futuro próximo como indicativos gerais de emissão nos territórios, a depender de uma melhor calibração dos algoritmos, eventuais melhorias do mapa de biomassa e um processo de homologação que consiga avaliar melhor as incertezas envolvidas.
Questões metodológicas¶
Dentre as questões metodológicas, está pendente a avaliação de alguns pressupostos, como:
Para casos de corte raso por queima total, é assumido que 100% da vegetação é emitida (coeficiente 1). O quanto esse pressuposto é forte?
Para o cômputo de emissão nos eventos de focos:
É assumido implicitamente que o foco queimou com a mesma potência durante 24 horas. Pode ou não ser uma premissa forte que precisa ser analisada.
É necessário confirmar se o FRP hoje em dia é um produto que já tem todas aquelas correções aplicada manualmente por Kaiser et al. (2012)
Confirmar a referência experimental da relação entre FRP e emissão dada por Kaiser et al. (2012), por exemplo checando se houve um experimento ou medições em solo junto com o satélite.
Data do mapa de biomassa¶
Ao adotar um mapa de carbono/biomassa de 2018 há uma premissa implícita de assumir a cobertura de 2018 como retroativa a eventos anteriores a essa data.
Ou seja, pode ser que o mapa indique menor presença de carbono caso seja usado para eventos ocorridos anteriormente a 2018.
Além disso, é possível que de 2018 até agora essas áreas também tenham sido alteradas, ou seja, já ter ocorrido uma perda que o sistema reporta associada a um dado evento.
Em resumo:
Estimativas pré-2018 podem ser conservadoras, isto é, pois a biomassa reportada em 2018 num local pode ser menor do que a biomassa existente na data do evento.
Mas estimativas pós-2018 tendem a ser melhores.
Uma possível correção seria utilizar também mapas mais antigos e computar as perdas referentes a uma dada a partir do mapa mais próximo daquela data.
No geral, as estimativas de emissão baseadas em mapas de carbono ainda possuem grandes incertezas, especialmente porque esses mapas ainda são produzidos com altas incertezas, o que deve ser melhorado no futuro com a disponibilidade de novos dados.
Desmatamento PRODES e PRODES Acumulado¶
Na importação do conjunto de dados PRODES, eventos foram separados em dois tipos:
Desmatamento acumulado até 2007, num tipo de evento
PRODES Acumulado.Desmatamento anual a partir de 2008, num tipo de evento
PRODES.
Vale notar, que, no caso de conjuntos de dados como PRODES, as datas não se referem a eventos propriamente ditos mas a valores anuais em cada recorte territorial.
A interface de pesquia do Alertas+ apenas permite a seleção anual dos dados PRODES e atualmente não permite a seleção de dados PRODES Acumulado, que apesar disso se encontram na base de dados e podem ser usados em cálculos específicos de desmatamento total acumulado até a data recente do conjunto.
Computação determinística, idempotência e reversibilidade¶
O sistema Alertas+ é de computação determinística –, isto é, rodando as importações seguidas vezes com o mesmo conjunto de dados de entrada produz-se o mesmo resultado.
Todos os importadores de dados possuem idempotência, ou seja, podem ser rodados mais de uma vez que produzirão o mesmo estado final de importação com o mesmo conjunto de dados de entrada. Evidentemente, conforme os dados são atualizados na origem o sistema tenderá a produzir resultados também atualizados.
O sistema não é de computação reversível, isto é, não há procedimento de reversão dos dados de saída que obtenham de volta os dados de entrada. Assim, a checagem dos dados resultadas para a homologação do sistema foi realizada através da comparação paralela feita manualmente por analistas de geoprocessamento.
Da ausência de eventos¶
A ausência de eventos registrados não é evidência da ausência de eventos ocorridos. Pode ocorer limitações na detecção dos sistemas sensores.
Descontando falsos positivos, pode-se supor que a quantidade real de eventos seja maior do que reportado pelo sistema por conta de eventuais falhas de detecção dos dados usados, ou seja, o sistema pode subestimar mas dificilmente sobrestimar os alertas.
Tratamento de sobreposições de eventos¶
Alguns conjuntos requerem um tratamento para evitar a sobreposição entre eventos.
No caso do DETER, as sobreposições não permitidas no sistema são as de poligonos de classes que envolvam a remoção completa e definitiva da cobertura florestal, que são representados pelas categorias 1 (desmatamento) e 2 (mineração). Os polígonos de outras categorias podem ter interseções internas – seria o caso por exemplo de um lugar que sobre várias queimadas sucessivas – ou externas com poligonos das classes 1 ou 2 – no caso de uma área que é inicialmente queimada ou degradada e depois desmatada.
Tratamento das bacias hidrográficas¶
As bacias hidrográficas não são tratadas como um recorte territorial adicional, mas sim de maneira especial.
Para evitar sobrecarregar o banco com novas interseções, o tratamento que é
dado é mediante um JOIN espacial: a cada polígono ou ponto resultante das
interseções dos eventos com os territórios é atribuída uma bacia, baseada na
posição do ponto ou do centroide.
Isto não traz imprecisões significativas, devido à diferença de escala entre as
bacias e os eventos, e é muito mais rápido, pois não sobrecarrega o sistema
duplicando o tamanho da tabela event_territory.
Tal metodologia tem o problema de não tolerar sobreposição entre polígonos no shape de bacias. É permitido que haja vazios, mas não sobreposições.
Por isso, e devido à extensão geográfica das bacias hidrográficas, que supera em varias ordens de magnitude ao tamanho médio dos desmatamentos e alertas integrados no sistema, propõe-se realizar o cruzamento dos eventos poligonais tendo como referencia o centroide de cada polígono, evitando realizar interseções nos próprios polígonos.
Essa alteração, que tem um erro mínimo associado, deve otimizar a performance do sistema.
Estima-se que seguindo essa metodologia o custo de integração da nova camada de análise tenha sido insignificante em termos de armazenamento e performance.
Agrupamento temporal de resultados¶
O sistema suporta a agregação temporal de eventos nas escalas diária, semanal, mensal, quadrimestral ou anual (“unidade temporal”).
No caso de conjuntos de escala anual (PRODES), os dados já são agregados anualmente na data de início do período (01/08/2019 para o Ano PRODES 2020, por exemplo).
Para conjuntos na escala mensal (SAD), agregações diárias e semanais não são suportadas.
A API do sistema possui opções para a agregação de eventos ocorrer no início ou no final de cada período, no caso de agregações semanais em diante.
Comparação entre sistemas¶
É importante levar em conta o recorte territorial na interface de pesquisa do Alertas+ quando se deseja comparar os dados apresentados pelo sistema com os dados brutos de cada conjunto.
Quando uma seleção é feita, o total e a área dos alertas reportados consideram a sobreposição dos mesmos com a seleção territorial realizada (intersecção dos eventos com os territórios).
Isto foi implementado através de uma desagregação dos eventos por território na
tabela event_territory do banco de dados.
Para cada território onde há sobreposição com um evento, haverá uma entrada em
event_territory para aquele evento, mas com geometrias diferentes dadas pela
intersecção do território com o evento. inclui mais de um território.
Consequentemente, aquilo que em alguns conjuntos de dados (como o DETER) é chamado de aviso/alerta/evento pode não ser exatamente o mesmo evento reportado pelo Alertas+ por conta da seleção territorial escolhida que apresentará apenas o trecho do alerta que está interseccionado com os territórios escolhidos.
Ou seja, dependendo da seleção feita, o alerta do dado original pode ser apresentado numa seleção apenas na porção em intersecção com o recorte territorial escolhido, tanto no polígono exibido quanto na quantificação da área atingida.
No caso da seleção mais abrangente do Alertas+ (por exemplo todos os municípios ou estados), haverá coincidência nos reportes pois não ocorre restrição territorial a ser aplicada.
Ainda, para evitar dupla contagem de números de eventos e área total, algumas seleções são restritas na consulta de eventos:
A seleção de quantidades de eventos possuem a restrição
DISTINCTno ID do evento, para evitar seleção e contagem duplicada de eventos.Os tipos de território
MUNeUFnão podem ser selecionados juntamente com outros tipos de território, já que as contagens de eventos (e possivelmente das áreas) ficariam duplicadas pois esses territórios estão sempre sobprepostos a áreas protegidas e seus buffers.
Ou seja, um alerta que originalmente cobria mais de um território pode se transformar em N eventos durante o cruzamento (desagregação dos eventos por território), mas que NÃO SERÃO exibidos duplicadamente nas seleções.
Como exemplo, um alerta ambiental com abrangência de duas ARPs se torna dois incidentes ambientais de area equivalente depois do processamento dos dados canônicos.
A situação é análoga para o caso de eventos pontuais, pois podem ocorrer num local com sobreposição territorial.
Unidades de medida alternativas¶
Na interface de consulta do Alertas+ é possível alternar entre unidades de medida (quilômetros quadrados, hectares etc), estando também disponível a expressão de áreas em:
Campos de futebol, usando para isso a padronização da CBF/FIFA de
105m x 68m.Estimativa de árvores maduras derrubadas para o bioma amazônico, baseada no artigo de Steege et al. (2003) A spatial model of tree α-diversity and tree density for the Amazon e que calcula a quantidade de árvores maduras por hectare de floresta em pé entre 400 e 750; o Alertas+ utiliza a média entre esses valores, ou 575 árvores maduras por hectare.
Tais valores, apesar de não constarem em sistemas padrões de medição, são de boa comunicação e auxiliam o público a entender o impacto dos eventos de pressão/ameaça.
Propósito geral¶
O sistema tem um propósito de diagnóstico socioambiental e incidência nas políticas públicas e por isso o critério não foi somente a acurácia científica como contundência e agilidade.
Não se trata de um sistema com cálculos demorados para obter precisão científica arbitrária ou mesmo forense, mas sim um sistema que produza com rapidez boas estimativas dentro de margens de erros toleráveis.
O sistema permite a pesquisa e seleção rápida de eventos, podendo ser complementado com uma análise detalhada dos dados brutos disponíveis.
São utilizados tanto dados próximos do tempo real (Near Real Time - NRT) quanto dados de re-análise (Science Ready).
Terminologia¶
Notas sobre nomenclatura.
Alertas¶
Uso da palavra “alerta” como sinônimo de evento na versão em português:
Ameaça: Representa uma medida do risco iminente de ocorrer desmatamento e degradação florestal no interior de uma ARP. O IMAZON utiliza uma distância de 10 km para indicar a zona de vizinhança de uma ARP na qual a ocorrência de desmatamento e degradação florestal indica ameaça.
Pressão: Ocorre quando o desmatamento se manifesta no interior da ARP, levando a perdas de serviços socioambientais e até mesmo à redução ou redefinição de limites da ARP. Ou seja, é um processo interno de degradação ambiental que pode levar a desestabilização legal e ambiental da ARP.
Alerta: Representa um aviso ou sinal de ocorrência de um evento de desmatamento e degradação florestal.
Focos de Calor: Detecção de locais com queima de vegetação por meio de imagens digitais de sensores em satélites. Os seguintes termos têm o mesmo significado: foco de queima, foco de queimada, foco de incêndio e foco ativo.
Área com desmatamento de corte raso: Ocorrência de supressão total da vegetação nativa.
Área com degradação florestal: Ocorrência de supressão parcial da vegetação nativa decorrente de atividades de exploração madeireira, queimadas ou mineração.
Quantidade de áreas desmatadas: Valor quantitativo de alertas de desmatamento.
Quantidade de áreas degradadas: Valor quantitativo de alertas de degradação florestal.
Áreas Protegidas¶
As áreas protegidas são locais delimitados e geridos que se destinam à preservação e uso sustentável de um conjunto representativo de ecossistemas de singular valor científico, cultural, educativo, estético, paisagístico ou recreativo. As tipologias de Áreas Protegidas são Unidades de Conservação, Terras Indígenas, Territórios Quilombola e áreas regulamentadas de uso comunitário.
Coleção de dados¶
É um conjunto de dados atribuído a uma mesma fonte, metodologia, etc. Pode se referir a alertas/eventos mas também de territórios.
Exemplos:
ISA.
DETER INPE (inclui Amazônia Legal e Cerrado).
PRODES INPE.
Amazon Dashboard SERVIR.
FIRMS VIIRS.
FIRMS MODIS.
SAD IMAZON.
Dataset¶
É um conjunto de dados distribuído num único pacote/arquivo. Uma mesma coleção pode ser composta por múltiplos pacotes. A depender da coleção, alguns pacotes podem ser incrementais enquanto outros podem representar todo um período ou períodos específicos do conjunto.
Coleções de dados também podem ter pacotes distintos de acordo com recortes específicos.
Exemplos:
A coleção Amazon Dashboard pode ter pacotes para as datas 20201231 e 20210506 representando períodos distintos de dados.
O DETER possui pacotes para Amazônia Legal e para o Cerrado, e o o arquivo
deter-amz-public-2021mar29.zipreferente a uma data, por exemplo 2021-03-29 e a um dataset (amz).
Shapefile¶
Um shapefile é um formato de armazenamento de dados de vetor para armazenar a posição, a forma e os atributos de feições geográficas. É armazenado como um conjunto de arquivos relacionados e contém uma classe de feição. Os shapefiles normalmente contêm feições grandes com muitos dados associados. Representa um arquivo dentro de um dataset, isto é um conjunto de dados geoespaciais dentro dentro de um pacote.
Exemplos: a coleção DETER possui datasets para Amazônia Legal e para o Cerrado (distribuídos em pacotes distintos).
Assim, uma mesma coleção pode ser alimentada por múltiplos importadores, cada um deles podendo trabalhar com múltiplos datasets e cada dataset pode ter múltiplos shapefiles. Coleções também podem ser obtidas diretamente de outras bases de dados.
Importador (importer)¶
É um procedimento de importação para uma coleção. Por exemplo, FIRMS VIIRS e FIRMS VIIRS Arquive são dois importadores distintos para a mesma coleção também de nome “FIRMS VIIRS”.
Fase (phase)¶
É uma etapa relativa à carga de dados do sistema. Por exemplo:
Estágio 0: conjuntos de dados que são requisitos para todos ou a maioria dos importadores de eventos. Compõem o estágio 0 dados como mapas de biomassa e cobertura vegetal assim como as tabelas de territórios.
Estágio 1: conjuntos de eventos de importação periódica.
Estágio (stage)¶
É uma etapa relativa à carga do banco de dados. Por exemplo, uma importação pode ser dividida nos seguintes estágios:
Extract: dados são extraídos de um ou mais locais de origem.
Load: dados são carregados numa base de dados.
Transform: dados são transformados para se adequarem a um modelo de dados.
Linha de importação (pipeline)¶
É a sequência de estágios na incorporação de dados por um importador.
Por exemplo, a sequência ELT é composta na sequência de estátgios Extract, Load e Transform.
Operação (operation)¶
No contexto dos importadores, cada estágio pode ser dividido em operações, que realizam tarefas específicas nos conjuntos de dados.
Exportador (exporter)¶
Um exportador é a contraparte do seu respectivo importador, realizando a exportação de dados usados ou processados pelo sistema para que possam ser utilizados por outros sistemas ou mesmo usados por outras pessoas e entidades que queiram manter suas próprias instâncias do Alertas+.
Enquanto que numa API ou outro sistema dinâmico os dados são consultados dinamicamente, a função dos exportadores é fazer uma exportação bruta, específica e/ou periódica dos dados.
Subsistema (subsystem)¶
É uma porção modular do Alertas+ responsável por rotinas especializadas.